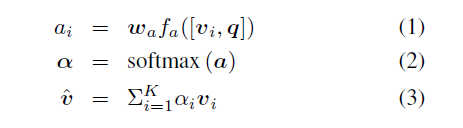Squeeze-and-Excitation Networks
在卷积网络的每一层,一些卷积核沿着输入通道方向表示相邻特征模式,在局部感受野(local receptive fields)的范围内融合空间及channel-wise特征信息。通过交错的组合卷积,下采样,非线性层等构建网络,CNN可以达到理论上的全局感受野(global theoretical receptive fields),以捕获图像的特征来进行图像的描述。最近的研究表明,将集成学习机制整合到CNN中可以提高网络的表示能力,Inception结构中嵌入了多尺度信息,聚合多种不同感受野上的特征来获得性能增益,还有进一步的工作是寻求更好地模拟空间依赖性,并将空间注意纳入网络的结构
文章跟以往的网络结构均不同,研究的是通道(channel)之间的关系。文章中提出了一种机制,允许网络执行特征重新标定,通过这种机制,网络可以学会使用全局信息,有选择地强调信息特征,抑制不太有用的特征

给定输入X,通过一系列的卷积操作变成特征通道数为C的U,执行Squeeze操作,顺着空间维度进行特征压缩,将每个二维的特征通道变为一个实数,这个实数在某种程度上具有全局感受野,随后是Excitation操作,采取简单的自选门机制的形式,将embedding作为输入,为每个通道生成权重,最后是Reweight操作,将输出的权重加权乘到通道特征上
可以通过简单地堆叠SE-block来组成SE-Net,也可以轻松地插入到其它网络中,虽然构建块的模板是通用的,但在整个网络中,它在不同深度执行的角色是不同的,在较低的层中,它以一种与类无关的方式激发信息特性,加强了共享的低层表示,随着层次的加深,SE-block变得越来越专门化,并以高度类特定的方式响应不同的输入,因此SE块实现的特征重标定的好处可以通过网络的层次积累
设计和实现一个新的CNN架构通常需要选择许多新的超参数和层配置,但是SE-block可以通过简单地替换组件,应用在SOTA模型中来提升性能,同时,SE-block在计算上是轻量级的,只轻微地增加模型复杂度和计算负担
相关工作
Deeper architectures
VGGNets和Inception models显示了提升网络的深度可以显著地提高网络的表达能力,ResNet证明了通过skip-connection,可以学习到更深更强的网络,Highway networks通过引入一个门控系统调节shortcut connections的信息流
另一个与之密切相关的研究方向集中于改进包含在网络中的计算元素的函数形式,分组卷积已被证明可以用来提升转换能力,通过多分支卷积可以实现更灵活的操作符组合,这可以被视为分组卷积的自然扩展。在之前的工作中,卷积通道的相关性通常被映射为特征的新组合,或者独立于空间结构,或使用1*1卷积核的标准卷积滤波器联合,这些研究大多致力于降低模型和计算复杂度,而作者认为,使用全局信息显式地建模通道之间的动态非线性依赖关系,可以简化学习过程,并显著增强网络的表征能力
Algorithmic Architecture Search
另有一部分研究在考虑放弃手工架构设计,求自动学习网络结构,该领域的许多早期工作是在神经进化领域进行的,该领域建立了用进化方法搜索网络拓扑的方法,尽管经常需要大量的计算,进化搜索已经取得了显著的成功,包括为序列模型找到良好的记忆细胞和学习用于大规模图像分类的复杂体系结构,为了减少这些方法的计算负担,学术界提出了有效的替代方法,Lamarckian inheritance和可微体系结构搜索,SE-block可以作为这些搜索结构的子模块,并且在工作中取得较高的效率
Attention and gating mechanisms
注意力机制就是将可用计算资源的分配偏向于信号中信息最丰富的部分,注意力机制已经在序列学习,图片定位和图像理解等task中展现了其效用
文章提出的SE块包含一个轻量级的门机制,该机制主要通过高效地对通道关系建模来增强网络的表征能力
SQUEEZE-AND-EXCITATION BLOCKS
SE-block是一个计算单元,可以建立在将$X \in R^{H’\times W’\times C’}$转化为$U \in R^{H \times W\times C}$的转换函数$F_{tr}$的基础上,我们用$V = [v_1, v_2,\dots v_C]$来表示滤波核集,那么有$U = [u_1, u_2,\dots u_C]$
这里的*代表卷积,$u_c \in R^{H\times W}$
由于输出是通过所有通道的总和产生的,因此通道依赖被隐式地嵌入到$v_c$中,但是与过滤器捕获的局部空间相关性相纠缠,由卷积建模的通道关系本质上是隐式的和局部的,作者希望通过明确地建模通道相互依赖关系来增强卷积特征的学习,这样网络就能够提高其对信息特征的敏感性,这些信息特征可以被后续转换利用,因此,作者希望为它提供获取全局信息的途径,并在它们被馈入下一个转换之前,分两个步骤squeeze 和excitation来重新校准
Squeeze: Global Information Embedding
为了利用通道相关性,文章首先考虑输出特征中每个通道的信号,每个学习滤波器都有一个局部感受野,因此变换输出U的每个单元都不能利用该区域之外的上下文信息
为了解决这个问题,作者将全局空间信息压缩(squeeze)到一个通道描述符中,这是通过全局池化来生成通道信息来实现的
Excitation: Adaptive Recalibration
信息压缩之后的操作则是要完全捕捉通道间的依赖关系,为了完成这个任务,这个函数需要具有两个特点:一是灵活(它必须能够学习通道之间的非线性相互作用),二是能够学习一种非互斥的关系,因为要允许多通道被强调(而不是强制一次性激活(enforcing a one-hot activation)),作者通过一个简单的门控机制和sigmoid函数来实现
$\delta$表示relu函数,$\sigma$表示sigmoid函数,$W_1 \in R^{\frac{C}{r}\times C}$,$W_2 \in R^{C\times \frac{C}{r}}$
用第一个FC层将$C$个通道压缩为$\frac{C}{r}$个通道来降低计算量,通过relu函数之后,再通过第二个FC层恢复到$C$个通道,然后用sigmoid函数计算
最后SE-block的输出为(也就是作者前文所说的Reweight)
$F_{scale}$即权重(Excitation的输出)和通道特征相乘的操作
Instantiations
以上是SE-block插入到Inception结构和含有skip-connections的模块
两个FC层中间夹一个relu的优点是
- 具有更多的非线性,可以更好地拟合通道间复杂的相关性
- 极大地减少了参数量和计算量
Resnet需要在Addition前对分支上Residual的特征进行了特征重标定,如果对Addition后主支上的特征进行重标定,由于在主干上存在0~1的scale操作,在网络较深BP优化时就会在靠近输入层容易出现梯度弥散的情况,导致模型难以优化
目前大多数的主流网络都是由这两种网络叠加构造的,因此SE-block可以比较容易地嵌入
实验
训练过程比较,可以发现嵌入了SE模块的网络可以收敛到更低的错误率上
SOTA模型的对比
Code
1 | class SEblock(nn.Module): |
inplace = true是覆盖运算(比如运算过程中是x=x+1,而不是y=x+1,x=y),这样可以节省运算内存
![支付宝]() 支付宝
支付宝