VIS2019论文整理(3)
[V] VAST,[I] InfoVis,[S] SciVis
VIS2019论文整理系列的最后一篇
之前的内容见:
Volume Visualization
[S] Void-and-Cluster Sampling of Large Scattered Data and Trajectories [PDF]
本文提出了一种基于统计抽样的分散数据的数据约简技术。该空隙和聚类采样技术找到一个代表子集,最优分布在空间领域的蓝色噪声。此外,它可以适应给定的密度函数,作者使用它来采样多变量值域中的高复杂度区域更多的人口。此外,该采样技术隐式地定义了样本的顺序,从而支持渐进式数据加载和连续的详细级别表示。并将技术扩展到采样时间依赖的轨迹,例如在一个时间间隔内的路径线,使用一种有效的迭代方法。此外,团队引入了一个局部和连续的误差度量来量化一组样本代表原始数据集的程度,在抽样时应用这个误差测量来指导抽样的数量。最后,作者团队使用这个误差度量和其他量来评估算法的质量、性能和可扩展性。
[S] FeatureLego: Volume Exploration Using Exhaustive Clustering of Super-Voxels [PDF]
本文提出了一个体积探索框架,FeatureLego,它使用一种新的体素聚类方法来有效地选择语义特征。团队将输入量划分为一组紧凑的超级体素,它们代表了最佳的选择粒度。然后使用基于图的聚类方法对这些超级体素进行详尽的聚类。与常用的参数采样方法不同,本文提出了一种有效的算法来执行这种穷举聚类。通过计算一组详尽的集群,目标是捕获尽可能多的边界,并确保用户有足够的选项来有效地选择语义相关的特征。此外,作者团队将所有经过计算的集群合并到一个元集群树中,该元集群可以用于分层探索。团队实现了一个直观的用户界面,使用本文的集群方法交互地探索卷。最后,在多个不同模式的真实数据集上展示了框架的有效性
[S] Interactive Visualization and On-Demand Processing of Large Volume Data: A Fully GPU-Based Out-Of-Core Approach [PDF]
在广泛的科学领域,3D数据集的生产能力近年来得到了广泛的发展,特别是随着其规模的快速增长。因此,许多大型应用程序,包括可视化或处理,都变得难以处理。解决这个问题的一个办法是提供核外算法,专门设计来处理比内存大得多的数据集。
本文提出了一种新的方法,它扩展了在gpu上的核外体积渲染领域中已经建立的广泛的交互式寻址原则,以允许在可视化阶段进行按需处理。本文提出设计一个管道,用于管理数据作为规则的3D网格,而不考虑底层的应用程序。它依赖于缓存方法与虚拟内存寻址系统耦合到GPU上的有效并行管理,以在交互时间提供有效的访问数据。它允许任何可视化或处理应用程序通过管理多模态数据集来利用其结构的灵活性。此外,作者证明,系统在单一标准PC上提供了良好的性能与GPU低内存预算
Geovisualization
[V] A Visual Analytics System for Exploring, Monitoring, and Forecasting Road Traffic Congestion [PDF]
本文提出了一个交互式的视觉分析系统,用于交通拥堵的探索,监视和预测基于车辆检测数据。通过领域专家的协作,团队提取了任务需求,合并了长时间的需求利用短时记忆模型进行拥塞预测,并设计了一种加权方法来检测拥塞产生的原因和拥塞的传播方向。本文的视觉分析系统旨在使用户探索拥堵的原因、方向和严重程度。一个城市的拥堵情况使用容积-速度河流(VSRivers)可视化,同时显示交通量和速度。为了评估系统,团队报告性能比较结果,其中本文的模型比其他预测算法更准确。本文通过三个案例研究和领域专家反馈来证明系统在交通管理和拥塞广播领域的有用性
[V] Semantics-Space-Time Cube: A Conceptual Framework for Systematic Analysis of Texts in Space and Time [PDF]
本文提出了一种分析数据的方法,其中文本与空间和时间参考相关联,目的是了解文本语义如何随时间和空间变化。为了表示语义,采用概率主题建模。在提取一组代表文本主题和主题权重向量后,团队汇总数据与对应的维度数据立方体的话题,空间位置的集合(例如,区域),和时间分成合适的间隔根据计划的规模分析。每个多维数据集单元格对应于一个组合(主题、位置、时间间隔),并包含用于描述与此主题相关的文本子集的聚合度量,并在这些位置和间隔内拥有空间和时间引用。在此基础上,系统地描述了分析任务的空间,探讨了语义、空间和时间这三个异构信息面之间的相互关系。本文介绍了立方体的投影和切片操作,这些操作用于将复杂任务分解为较简单的子任务。然后,展示了可视化分析系统的设计,旨在支持这些子任务。为了降低用户界面的复杂性,本文应用了结构、视觉和操作一致性的原则,同时尊重每个方面的具体属性。聚合的数据以三个平行视图表示,它们对应于这三个方面,并提供数据的不同互补视图。在方面细节允许的范围内,视图具有相似的外观和感觉。适用于任何视图的统一交互操作支持在facet之间建立链接。均匀性原理也应用于支持数据立方体上的投影和切片操作。本文通过将其应用于两种分析场景来评估该方法的可行性和实用性,使用地理定位的社交媒体数据来研究人们对不同时空尺度的社会和自然事件的反应。
Ensembles & Uncertainty
[I] Uncertainty-Aware Principal Component Analysis [PDF]
本文提出了一种技术,对受不确定性影响的数据进行降维。该方法是对传统主成分分析(PCA)的推广,以多元概率分布。与非线性方法相比,线性降维技术具有投影后概率分布特征保持不变的优点。团队推导了基于每个输入的潜在不确定性的主成分分析样本协方差矩阵的表示,为新方法——不确定性感知主成分分析——建立了数学基础。除了通过基于采样策略的方法获得的准确性和性能之外,公式允许数据中的不确定性进行敏感性分析。为此,作者建议将因子轨迹作为一种新颖的可视化方法,能够更好地理解不确定性对所选主成分的影响。本文提供了多个使用真实数据集的技术示例。作为一个特例,本文展示了如何通过闭形式的PCA来传播多元正态分布。此外,讨论了方法的扩展和局限性
[S] A Structural Average of Labeled Merge Trees for Uncertainty Visualization [PDF]
科学和工程中的物理现象经常用标量场来建模。在标量场拓扑中,常用基于图的拓扑描述符,如归并树、轮廓树和Reeb图来表征标量场(子)层集合的拓扑变化。推进基于拓扑的可视化的最大挑战和机遇之一是理解并将不确定性纳入到这种拓扑描述符中,从而有效地推断其基础数据
本文研究了一组标记合并树的结构平均,并利用它对数据中的不确定性进行编码。具体地说,计算一个1-中心树,它在一个定义良好的度量称为交错距离的条件下最小化它与集合中任何其他树的最大距离,本文提供启发式策略来计算标签不完全一致的合并树的结构平均值,进一步提供了一个交互式可视化系统,它类似于一个数字计算器,以一组合并树作为输入,并输出一棵树作为它们的结构平均值。还强调了输入和平均值之间的结构相似性,并将不确定性信息用于视觉探索。通过输入树的度量空间视图,团队开发了一种新的不确定性度量,称为一致性。最后,通过从标量域集合中产生的合并树演示了框架的应用。本文的工作是第一个使用交叉距离和一致性来研究一个全局的,数学上严格的,不确定性可视化背景下的结构平均归并树
[S] Multiscale Visual Drilldown for the Analysis of Large Ensembles of Multi-Body Protein Complexes [PDF]
在研究多体蛋白质复合物时,生物化学家使用计算工具,可以提出数百或数千种可能的空间构型。然而,这难以被实验验证
本文提出了一种新的多尺度视觉钻取方法,该方法是与蛋白质组学专家紧密合作设计的,能够系统地探索构型空间。本文的方法利用了数据的层次结构——从蛋白质复杂构型的整个集合到单个构型,它们的接触界面,以及相互作用的氨基酸。本文的新解决方案基于交互链接的2D和3D视图,在每个层次上,提供一组选择和过滤操作,使用户能够缩小需要手动检查的配置数量。此外,团队提供了一个专用的过滤界面,它为用户提供了应用过滤操作的概述,并使他们能够检查它们对已探索的集成的影响。通过这种方式,维护了探索过程的历史,从而使用户能够返回到探索的早期点。本文通过与蛋白质组学专家合作进行的两个案例研究证明了方法的有效性。
[S] eFESTA: Ensemble Feature Exploration with Surface Density Estimates [PDF]
本文提出地表密度估计(SDE)来模拟三维集成模拟数据中的地表特征(等值面、山脊面和流面)的空间分布。SDE计算的输入为以多边形网格表示的地物,不需要场数据集(例如标量场或向量场)。SDE定义为输入曲面上无穷多点集的核密度估计,通过累积三角形斑块的表面密度来逼近。本文还提出了一个算法来指导选择合适的核带宽进行SDE计算。提出了基于表面密度估计(eFESTA)的探测方法来提取和可视化集成地物的主要趋势。对于表面特征的集合,每个表面首先根据其对SDE的贡献转换成密度场,然后根据密度场之间的成对距离将密度场组织成层次表示。然后使用分层表示法来指导密度场以及下垫面特征的视觉探索。本文证明了方法在系综标量场中的应用,不确定非定常流中的拉格朗日相干结构,以及系综流体流中的流面。
[S] Visualization and Visual Analysis of Ensemble Data: A Survey [PDF]
可视化和可视化分析在探索、分析和呈现科学数据方面发挥着重要作用。在许多学科中,数据和模型场景正变得多面化:数据常常是时空和多变量的;它们来自不同的数据源(多模态数据),来自多个模拟运行(多运行/集成数据),或者来自交互现象的多物理模拟(耦合模拟模型产生的多模型数据)。此外,数据可以具有不同的维度,或者在各种类型的网格上结构化,这些网格需要在可视化中关联或融合。数据特征的这种异质性为可视化研究带来了新的机遇和技术挑战。因此,可视化和交互技术经常与计算分析相结合。在本调查中,团队研究现有的方法可视化和交互式视觉分析的多面科学数据。基于一个彻底的文献回顾,一个分类的方法被提出。本文涵盖了广泛的领域,并讨论了不同的挑战在何种程度上与可视化和可视化分析的现有解决方案相匹配。这就引出了关于有前途的研究方向的结论,例如,为多运行和多模型数据寻求新的解决方案,以及支持多个方面的技术
[V] Exploring the Sensitivity of Choropleths under Attribute Uncertainty [PDF]
choropleth地图是空间数据分析的重要工具。然而,空间单元的基本属性值对生成choropleth地图的统计分析和地图分类过程有很大的影响。如果属性值包含一系列的不确定性,一个关键的任务就是确定不确定性对地图可视化和统计分析的影响有多大。
本文提出了一个可视化分析系统,它增强了对属性不确定性对数据可视化和数据统计分析的影响的理解。该系统包括基于平行坐标的不确定度规范视图、基于区域和基于仿真分析的冲击河和冲击矩阵可视化,以及用于可视化属性值不确定性范围内分类和空间自相关变化的双索线图和t-SNE图。本文通过三个用例来说明属性不确定性对地理分析的影响
Interactive Machine Learning
[I] Illusion of Causality in Visualized Data [PDF]
经常吃早餐的学生平均分往往更高。从这些数据中,许多人可能会自信地说,上学前的早餐计划会带来更高的分数。这是一个推理错误,因为相关性并不一定表明因果关系——X和Y可以相互关联,而不直接导致另一个。虽然这种错误是普遍存在的,但它的普遍性可能会被放大或缓解的方式的数据呈现给观众。通过三个众包实验,作者团队检验了简单的数据关系如何被呈现,是否会减少这种推理错误。第一个实验测试了类似于早餐- gpa关系的例子,但因果关系的似然性有所不同。让参与者评价他们对相关关系的认同程度,他们认为这是适当的高。然而,参与者也对数据的因果解释表示高度一致。对因果解释的支持程度在各种可视化类型中并不相同:文本描述和柱状图的因果关系评分最高,但散点图的因果关系评分较低。但是,这种效果是由条形图将数据聚合为两组驱动的,还是由视觉编码类型驱动的呢? 本文分离了数据聚合和视觉编码类型,并检查了他们各自对感知因果关系的影响。总的来说,不同的可视化设计对相同的数据提供不同的认知推理启示。高水平的图表数据聚集往往与较高的感知因果关系的数据。参与者认为线和点的视觉编码比条形编码更具有因果性。研究结果表明,一些可视化设计是如何触发更强的因果关系的,而选择其他的可以帮助减轻对因果关系的不合理的看法。
[V] Ablate, Variate, and Contemplate: Visual Analytics for Discovering Neural Architectures [PDF]
深度学习模型需要多个层次和参数的配置,才能获得较好的效果。然而,目前很少有关于如何配置成功模型的系统指导方针。这意味着模型构建者通常必须通过手工编程不同的架构(这是乏味和耗时的)来试验不同的配置,或者依赖于纯自动化的方法来生成和培训架构(这是昂贵的)。
在本文中,作者团队对模型架构和参数,或REMAP,一个可视化分析工具,允许模型构建者通过探索和快速实验的神经网络架构快速发现深度学习模型。在REMAP中,用户使用全局检查和局部实验相结合的方法来探索神经网络结构的大而复杂的参数空间。通过一组模型的可视化概述,用户可以识别出感兴趣的架构集群。基于他们的发现,用户可以运行消融和变化实验,以确定在给定架构中添加、删除或替换层的影响,并相应地生成新的模型。他们还可以使用简单的图形界面手工制作新的模型。因此,模型构建器可以快速、高效地构建深度学习模型,而无需手工编程。团队通过四名深度学习模型构建器的设计研究来设计REMAP。本文通过一个用例演示了REMAP允许用户通过模型空间使用视觉探索和用户定义的半自动搜索有效地发现性能神经网络架构
[V] VASSL: A Visual Analytics Toolkit for Social Spambot Labeling [PDF]
社交媒体平台充斥着社交垃圾邮件。检测这些恶意帐户是必要的,但具有挑战性,因为他们不断演变,以逃避检测技术
本文介绍了VASSL,一个可视化分析系统,可以帮助检测和标记垃圾邮件机器人。该工具提供了多个连接视图,并利用维数减少、情感分析和主题建模,从而提高了人工标记的性能和可伸缩性,从而为识别垃圾邮件机器人提供了洞察。该系统允许用户以交互的方式选择和分析帐户组,从而能够检测到在单独检查时可能无法识别的垃圾邮件机器人。本文提出了一项用户研究,以客观地评估VASSL用户的性能,以及获取关于工具的有用性和易用性的主观意见。
[V] Visual Interaction with Deep Learning Models through Collaborative Semantic Inference [PDF]
当人类在决策过程中失去代理权时,任务的自动化会产生重要的后果。深度学习模型尤其容易受到影响,因为目前的黑箱方法缺乏可解释的推理。作者认为,深度学习系统的视觉界面和模型结构都需要考虑交互设计。本文提出了一个协作语义推理(CSI)框架,用于交互和模型的协同设计,以实现人与算法之间的可视化协作。该方法揭示了模型的中间推理过程,允许与问题的可视隐喻进行语义交互,这意味着用户可以理解和控制模型推理过程的各个部分。文章中通过一个共同设计的文件摘要系统的案例研究来论证CSI的可行性
[V] ICE: An Interactive Configuration Explorer for High Dimensional Parameter Spaces [PDF]
在许多应用程序中,用户试图探索几个分类变量的设置对一个因变量的影响。例如,计算机系统分析人员可能希望研究文件系统或存储设备的类型如何影响系统性能。一种常用的方法是采用并行集的方法来可视化多元范畴变量。然而,作者发现参数对数值变量的影响程度在这里不容易观察到。团队也尝试了一种基于多重对应分析的降维方法,但发现svd生成的2D布局导致了信息的丢失。因此,本文提出了一种新的方法,交互式配置浏览器(ICE),它直接解决了分析人员了解因变量如何受到给定多个优化目标的参数设置的影响的需求。没有任何信息丢失,因为ICE显示了在每个分类变量的背景下的因变量的完整分布和统计。分析人员可以交互地过滤变量,以优化特定的目标,如实现一个具有最大性能、低方差等的系统。本文的系统是在与一组系统性能研究人员的紧密合作下开发的,它的最终有效性是通过专家访谈、比较用户研究和两个案例研究来评估的。
[V] Interactive Correction of Mislabeled Training Data [PDF]
在本文中,团队开发了一种可视化的分析方法来交互地提高标记数据的质量,这对于监督和半监督学习的成功至关重要。通过使用用户选择的可信项来提高质量。为了精确匹配可信项的标签,使训练损失最小化,团队采用了双层优化模型。在此基础上,开发了一种可扩展的数据校正算法,有效地处理成千上万的标注数据。增加的tSNE有助于可信项的选择,提高了计算效率和布局稳定性,确保不同级别之间的平稳过渡。通过定量评价和案例研究,在真实数据集上评估了本文的方法,结果普遍良好。
Infographics & Storytelling
[I] Text-to-Viz: Automatic Generation of Infographics from Natural Language Statements [PDF]
通过将数据内容与视觉装饰结合起来,信息图可以有效地以一种引人入胜、令人难忘的方式传递信息。各种创作工具已经被提议来促进信息图的创建。然而,使用这些创作工具创建专业的信息图仍然不是一件容易的任务,需要大量的时间和设计专业知识。因此,这些工具通常对普通用户没有吸引力,他们要么不愿意花时间学习这些工具,要么缺乏创建专业信息图的设计专业知识
在本文中,探索了一种替代的方法:从自然语言语句中自动生成信息图。首先对信息图的设计空间进行了初步的研究。在初步研究的基础上,建立了一个概念证明系统,该系统可以自动地将简单的比例相关统计信息转换为一组预先设计样式的信息图。最后,通过样本结果、展示和专家评审来演示系统的可用性和有用性。
[I] Towards Automated Infographic Design: Deep Learning-based Auto-Generation of Extensible Timeline [PDF]
设计人员在创建信息图时,不仅要考虑感知效果,还要考虑视觉风格。对于专业设计师来说,这个过程既困难又耗时,更不用说非专业用户了,这就导致了对自动信息图设计的需求。作为第一步,本文关注时间线信息图,它已经被广泛使用了几个世纪。本文提供了一种端到端的方法,可以从位图图像中自动提取可扩展的时间轴模板。本文的方法采用了解构和重构的范式。在解构主义阶段,本文提出一个多任务同时深层神经网络解析两种类型的信息从位图时间表:1)全球信息,即表示,规模、布局,和方向的时间表,和2)当地的信息,例如,位置、类别、像素时间轴上的每一个视觉元素。在重构阶段,本文提出了三种技术的管道,即非最大合并、冗余利用解构结果,从信息图中提取可扩展模板。为了评估方法的有效性,本文合成了一个时间轴数据集(4296幅图像),并从互联网上收集了一个真实的时间轴数据集(393幅图像)。本文首先报告定量评估结果,方法在两个数据集。然后,给出了自动提取模板和基于这些模板自动生成时间线的例子,以定性地展示性能。结果表明,本文方法可以有效地从现实的时间轴信息图中提取可扩展模板
[V] EmoCo: Visual Analysis of Emotion Coherence in Presentation Videos [PDF]
情感在人类交流和公众演讲中扮演着关键的角色。人类的情感通常是通过多种方式表达的。因此,探索多模态情绪及其连贯性,对于理解表达中的情绪表达,提高表达技巧具有重要价值。然而,手动观看和学习演示视频往往是乏味和费时的。缺乏工具的支持来帮助进行有效和深入的多层次分析。因此,本文中介绍了EmoCo,一个交互式的视觉分析系统,以促进高效的分析情绪连贯性的面部,文本和音频模式的演示视频。该可视化系统具有通道连贯视图和句子聚类视图,这两个视图共同使用户能够快速获得情感连贯及其时间演化的概况。此外,细节视图和词视图可以分别从句子层次和词层次进行详细的探索和比较。本文通过基于TED Talk视频的两个使用场景和与两位领域专家的访谈,对提出的系统和可视化技术进行了全面的评估。结果证明了系统在理解表达中的情感连贯性方面的有效性。
[V] Multimodal Analysis of Video Collections: Visual Exploration of Presentation Techniques in TED Talks [PDF]
虽然许多教育领域的研究已经揭示了许多演示技巧,但它们经常是重叠的,有时甚至是矛盾的。探索在TED演讲中使用的演示技巧可以为实际指导提供证据。本研究旨在探讨从TED演讲中收集的语言和非语言表达技巧。然而,这种分析具有挑战性,因为分析由帧图像、文本和元数据组成的多模态视频集合非常困难。本文提出了一种视频集合中多模态内容的可视化分析系统。该系统具有三种不同层次的视图:带有新颖符号的投影视图,便于对表示风格进行聚类分析;比较视图显示时间分布和表示技术的并发性,支持聚类内分析;以及视频视图,以实现对视频的情境化探索。作者团队与语言教育专家和大学生一起进行案例研究,为方法的有效性提供轶事证据,并报告有关TED演讲中演讲技巧的新发现。来自用户研究的定量反馈证实了本文的视觉系统对视频采集的多模态分析的有用性
[V] Supporting Story Synthesis: Bridging the Gap between Visual Analytics and Storytelling [PDF]
视觉分析通常处理复杂的数据,并使用复杂的算法、视觉和交互技术来支持分析。分析的结果和结果通常需要向缺乏视觉分析专业知识的受众进行交流。这要求分析结果以比通常在视觉分析系统中使用的更简单的方式呈现。然而,不仅分析性可视化对于目标受众来说过于复杂,而且需要呈现的信息也过于复杂。分析结果可能由多个组件组成,这些组件可能涉及多个异构方面。因此,在从获得分析结果到传达分析结果的过程中存在着差距,其中存在两个主要的挑战:信息复杂性和显示复杂性。
为了解决这个问题,本文提出了一个通用框架,在这个框架中,数据分析和结果展示通过故事合成连接起来,在这个框架中,分析师创建并组织故事内容。与以前的研究不同,在以前的研究中,分析结果由存储的显示状态表示,作者将其视为数据构造。本文专注于选择、聚集和组织研究结果以进行进一步的展示,而不是跟踪分析历史和启用数据显示的双重(即探索性和交流性)使用。在故事合成中,研究结果被选择、组合和安排在有意义的布局中,这些布局考虑到信息的结构及其组成部分的内在属性。本文提出了一个工作流,用于在设计视觉分析系统时应用所提出的概念框架,并通过将其应用于两个不同的领域(社交媒体和运动分析)来演示该方法的通用性
Visualization in Medicine
[I] CerebroVis: Designing an Abstract yet Spatially Contextualized Cerebral Arteries Network Visualization [PDF]
人类大脑中的血液循环是通过大脑动脉网络提供的。如果临床医生怀疑病人有中风或其他脑血管疾病,他们会要求进行影像学检查。神经放射学家会对扫描结果进行视觉检查,看是否有异常。它们的视觉搜索任务对应于浏览和路径跟踪等抽象的网络分析任务。
为了协助神经放射学家识别脑动脉异常,本文设计了一种新的脑动脉网络可视化抽象方法——脑动脉网络可视化。在这项设计研究中,团队根据网络理论对大脑动脉系统提出了一个新的框架和定义,并将神经放射学家的领域目标描述为抽象的可视化和网络分析任务。通过一个迭代的,以用户为中心的设计过程,团队开发了一种抽象的网络布局技术,它结合了大脑动脉的空间脉络。抽象可视化能够提高三维几何表示的域任务性能,而包含空间上下文有助于保存用户对底层几何图形的心理映射。团队提供了网络布局技术和脑动脉可视化工具原型的开源实现。通过成功地布置出61个开源大脑扫描来证明技术的健壮性。本文通过与三位神经放射学家的混合方法研究来评估布局的有效性。在形成性对照实验中,研究参与者使用脑血管成像和传统3D可视化检查真实的脑动脉成像数据,以确定模拟颅内动脉狭窄。参与者更准确地识别狭窄使用脑血管病(绝对危险差13%)
[S] Cohort-based T-SSIM Visual Computing for Radiation Therapy Prediction and Exploration [PDF]
本文描述了一种基于队列患者空间相似性的放射治疗(RT)计划的视觉计算方法。在头颈部癌症的放射治疗中,肿瘤周围危险器官的剂量是造成治疗毒性的主要原因。随着患者资源库的可用性,这种情况使得临床医生有兴趣基于以前治疗过的类似患者来理解和预测RT结果。为了实现这类分析,本文引入了一种新的基于拓扑的空间相似度度量T-SSIM,以及基于这种相似度度量的预测算法。将算法与视觉导向界面相结合,该界面将空间数据和统计结果的视觉编码交织在一起,包括一种新颖的可感知空间的平行标记编码。本文报告了165名患者队列的定量结果,以及与正在远程合作的放射肿瘤学、数据管理、生物统计学和医学影像领域专家的定性评估。
[S] DeepOrganNet: On-the-Fly Reconstruction and Visualization of 3D / 4D Lung Models from Single-View Projections by Deep Deformation Network [PDF]
本文介绍了一种基于深度神经网络的方法,即DeepOrganNet,来实现完全高保真度的生成和可视化基于复杂背景的单视图医学图像的3D/4D器官几何模型。统的3D / 4D医学图像重建需要近数百个投影,这将耗费难以忍受的计算时间,并给人体受试者带来令人不快的高成像/辐射剂量。此外,后续要分割或提取出准确的三维器官模型,还需要进一步操作。减少投影次数可以减少计算时间和成像剂量,但重构图像的质量会相应下降。
据本文作者所知,目前还没有一种方法可以直接、明确地从一幅二维医学灰度图像中实时重建多个三维器官网格。对于单视图的二维医学图像,如3D / 4D-CT投影或x射线图像,本文的端到端深度网络框架可以有效地重建图像,通过学习基于三元张量积变形技术的多个模板的平滑变形场,利用从输入的二维图像中提取的具有信息的潜在描述符,建立具有各种几何形状的3D/4D肺模型。该方法能够保证3D/4D肺模型生成高质量、高保真度的多种网格;而目前所有基于单一图像形状重建的深度学习方法都不能。这项工作的主要贡献是在二维单视图投影中精确地重建三维器官形状,显著地提高了实现实时可视化的程序时间,并显著地降低了人体受试者的成像剂量。实验结果评估和比较与传统的重建方法和先进的深度学习,通过使用广泛的3D和4D示例,包括合成的幻影和真实的患者数据集。该方法在实时图像引导放射治疗(IGRT)中具有很大的应用潜力,只需数毫秒即可生成顶点为10K的器官网格。在实时图像引导放射治疗(IGRT)中有很大的应用潜力
[V] Motion Browser: Visualizing and Understanding Complex Upper Limb Movement Under Obstetrical Brachial Plexus Injuries [PDF]
臂丛是一个复杂的外周神经网络,它能够感知和控制手臂和手的运动。如今,肌肉之间产生简单运动的协调性仍然没有被很好地理解,阻碍了如何最好地治疗这类周围神经损伤患者的知识的探索。为了获得足够的信息用于医疗数据分析,医生对患者进行运动分析评估,以产生丰富的数据集,这些数据来自于真实任务中记录的多个关节运动的肌肉。但是,目前还没有以简洁和可解释的方式分析和可视化数据的工具。由于无法在一个平台上集成、比较和计算多个数据源,医生只能通过简单的统计值来模糊地描述患者的行为,从而限制了回答临床问题和生成研究假设的可能性。为了应对这一挑战,本文提出了运动浏览器,一个交互式的视觉分析系统,它提供了一个有效的框架来提取和比较肌肉活动模式从病人的四肢和协调视图,以帮助用户分析肌肉信号,运动数据和视频信息,以解决不同的任务。该系统是计算机科学家、骨科医生和康复医生共同努力的结果。目前的案例研究表明,医生可以利用这些信息来理解个体如何协调他们的肌肉来发起适当的治疗,并为未来的研究产生新的假设。
Words & Documents
[V] LDA Ensembles for Interactive Exploration and Categorization of Behaviors [PDF]
本文将行为定义为某个参与者在一段时间内执行的一组动作。考虑分析多个参与者的大量行为集合的问题,更具体地说,识别典型行为和发现异常行为。文中提出了一种利用主题建模技术——LDA(潜在Dirichlet分配)集合——来表示通过对行为集合进行主题建模而获得的典型行为类别。当将这些方法应用于自然语言文本时,通常根据与主题相关的术语的语义相关性来判断所提取主题的质量。然而,这个标准并不一定适用于从非文本数据中提取的主题,比如动作集,因为动作之间的关系可能并不明显。
本文开发了一套可视化和交互式技术,支持基于其他标准(如行为集的独特性和覆盖范围)构建适当的主题组合。两个分析安全管理系统运行行为和游乐园参观行为的案例,以及专家对第一个案例的评价证明了方法的有效性
[I] ShapeWordle: Tailoring Wordles using Shape-aware Archimedean Spirals [PDF]
本文提出了一种新技术,可以创造形状为界的文字,作者称其为ShapeWordle,可以把文字变成一个给定的形状。为了在形状内指导单词的放置,本文扩展了传统的阿基米德螺旋,通过使用形状的距离场以差分形式表示螺旋,使其具有形状感知能力。为了处理非凸形状,本文引入了一种多中心Wordle布局方法,该方法将形状分割成可感知形状的螺旋部分,以自适应地填充空间并生成单词位置。此外,还提供了一组编辑交互,以方便创建语义上有意义的文字。最后,文中提供了三个评价: 比较本文的结果与最先进的技术(WordArt),14个用户的案例研究,以及一个展示技术覆盖范围的画廊
[V] Semantic Concept Spaces: Guided Topic Model Refinement using Word-Embedding Projections [PDF]
本文提供了一个框架,该框架允许用户合并他们的领域知识的语义来细化主题模型,同时保持模型不可知。该方法使用户能够(1)理解模型的语义空间,(2)识别潜在冲突和问题的区域,(3)根据概念的理解重新调整概念的语义关系,直接影响主题建模。这些任务由交互式可视化分析工作空间支持,该工作空间使用文字嵌入投影来定义概念区域,然后可以细化概念区域。用户改进的概念独立于特定的文档集合,可以转移到相关的语料库中。概念空间内的所有用户交互直接影响基础向量空间模型的语义关系,进而改变主题建模。除了直接操作之外,本文的系统通过推荐的交互来指导用户的决策过程,指出潜在的改进。他的目标细化旨在最小化有效的人在循环过程所需的反馈。团队在两项用户研究中证实了方法所取得的进步,这两项研究显示,通过视觉知识外部化和学习过程,主题模型的质量得到了提高
[V] VIANA: Visual Interactive Annotation of Argumentation [PDF]
摘要论证挖掘解决的是识别论证文本片段的边界并提取它们之间的关系这一具有挑战性的任务。完全自动化的解决方案不能达到令人满意的准确性,因为它们没有充分地结合语义和领域知识。因此,专家目前依赖于耗时的手工注释。
本文提出了一个可视化的分析系统,通过自动建议哪些文本片段需要注释来增强手工注释的过程。随着时间的推移,通过结合语言知识和语言建模,从用户交互中学习论证相似度的度量,这些建议的准确性得到了提高。基于与领域专家的长期协作,团队确定并建模5个高级分析任务。可以仔细阅读和做笔记,注释论点,论点重建,提取论点关系,和探索论点图。为了避免上下文切换,团队通过无缝变形在所有视图之间转换,在视觉上锚定所有基于文本和图形的层。团队通过基于总统辩论语料库的两阶段专家用户研究来评估我们的系统。结果显示,与现有的解决方案相比,专家更喜欢本文的系统,因为自动建议提供了加速,并且文本和图形视图之间的紧密集成。
[I] An Evaluation of Semantically Grouped Word Cloud Designs [PDF]
:词云仍然是总结文本信息的流行工具,尽管它们在分析任务方面存在文档化的缺陷。它们的受欢迎程度很大程度上取决于它们有趣的视觉吸引力。本文中展示了一系列控制实验的结果,这些实验表明,与标准的单词云布局相比,将单词排列成语义和视觉上截然不同的区域的布局对于理解底层主题更有效。与标准的文字布局相比,留白分隔符和/或空间分组的颜色编码能够显著增强对基本主题的理解,同时在审美上也获得更高的评分。这项工作是之前关于词云语义布局研究的一个进步,因为之前的研究没有确保不同的语义组在视觉上或语义上是不同的,或者没有进行可用性研究。这项工作的另一个贡献是为语义类别识别任务开发了一个数据集,该数据集可用于这些结果的复制或词云设计的未来评估
What’s the Difference?
[I] The Perceptual Proxies of Visual Comparison [PDF]
视觉化中的感知任务通常涉及比较。在两个图表中描述的两组值中,哪一组的值总体上最高?哪个范围最广?之前的经验研究发现,在不同的视觉比较任务(如“最大的delta”、“最大的相关性”)中,不同的标记组合和空间安排的表现差别很大。
本文在两个新的比较任务的经验评价中扩展了这些组合,两组值之间的“最大平均值”和“最大范围”。团队使用阶梯程序滴定数据比较的困难程度,以评估哪个安排对每个任务产生最精确的比较。作者发现,一些图表安排比其他图表更支持最大平均值和最大范围的可视化比较,而且这个模式与其他任务的模式有本质上的不同。为了综合这些不和谐的发现,作者认为必须理解可视化的哪些特征实际上被人类视觉系统用来解决给定的任务。文中称之为感知代理。例如,当比较两个柱状图的平均值时,视觉系统可能会使用“平均长度”代理来隔离柱状图的实际长度,然后在这些长度上构造一个真正的平均值。或者,它可以使用“船体面积”代理,感知每个图表的条形框所限定的隐含船体,然后比较这些船体的面积。本文提出了一系列跨越不同任务、标记和空间安排的潜在代理。这些代理的简单模型可以通过在这些标记、安排和任务中匹配它们的性能和人类性能来对其解释力进行实证评估。团队使用这个过程来突出感知代理的候选,这些代理可能扩展到更广的范围来解释视觉比较中的表现。
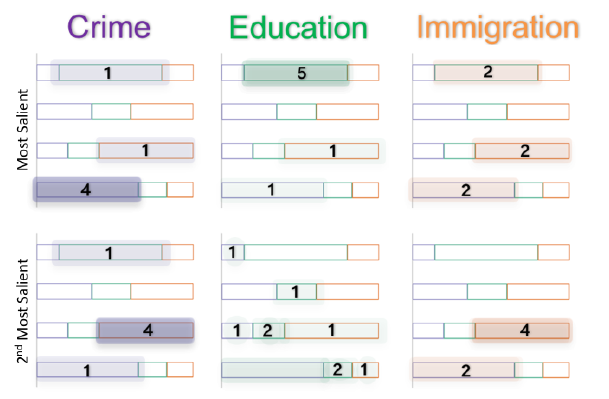
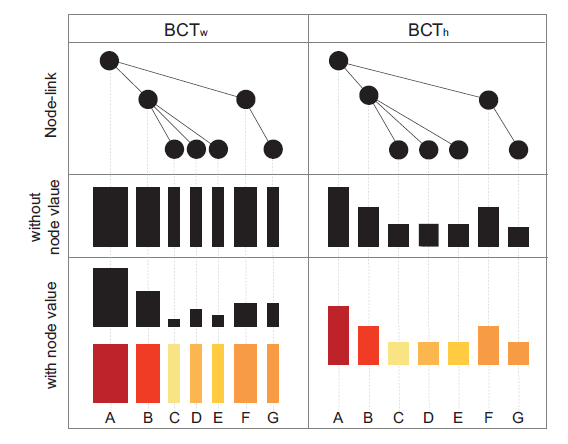
[I] BarcodeTree: Scalable Comparison of Multiple Hierarchies [PDF]
本文提出了一种新的可视化技术BarcodeTree (BCT),用于比较多棵树的拓扑结构和节点属性值。BCT可以同时提供100个浅层且稳定的树的概览,而不需要聚合单个节点。每个BCT使用类似于条形码的样式在单行中显示,允许树垂直堆叠,匹配节点水平排列,以方便比较并保持空间效率。团队设计了一些视觉线索和交互技术来帮助用户理解树的拓扑结构和比较树。在两种BCT变异与冰柱图的比较实验中,结果表明BCT降低了不同树之间的垂直距离,使树之间的比较更加直观。文中还提供了两个案例研究,涉及数百棵树的数据集,以演示BCT的效用。
[I] Comparison of Radial and Linear charts for Visualizing Daily Patterns [PDF]
通常认为径向图不如线性图有效。也许唯一的例外是可视化周期依赖时间的数据,这被认为是自然支持径向布局。事实证明,径向图的缺点超过了这种自然制图的优点。作为一种特殊情况,日常模式的可视化还没有系统地利用放射状图进行评价。与每年或每周的循环趋势相比,在放射状图上分析每日模式可能得益于文化中普遍存在的放射状时钟方面训练有素的技能。在一项有92名非专家用户参与的众源实验中,团队评估了用于可视化日常交通事故模式的径向图和线性图的准确性、效率和主观评分。团队系统地比较并列的12小时变体和单一的24小时变体在四个低级任务和一个高级解释任务中两个布局。结果表明,在所有的任务中,最基本的24小时线性柱状图是最准确和有效的,也是用户的首选。这为线性布局的使用提供了有力的证据——即使是为了可视化每天的周期模式。
[I] Aggregated Dendrograms for Visual Comparison Between Many Phylogenetic Trees [PDF]
本文处理在进化生物学中出现的多种系统发育树的视觉比较,特别是在一个参考树和几十到数百个其他树的集合之间。团队将系统发育树比较的领域问题抽象为寻找假设的支持或冲突证据的任务,这些假设需要在树集的不同细节层次上检查拓扑结构和属性值。本文引入了聚合树状图的新的视觉编码习惯,以根据有生物学意义的标准简明地总结交互选择的焦点子树之间的拓扑关系,并提供了一种自动适应可用屏幕空间的布局算法。
本文设计并实现了ADView系统,它在多个视图的多个详细层次上表示树:整个集合、树的子集、单个树、感兴趣的特定子树和单个分支层。团队将ADView开发的算法作为基准,将其信息密度与以前的工作进行比较,并通过使用最近发表的系统发育分析数据和专家使用真实数据的案例研究(从总结性访谈研究中提取),展示其在快速收集关于生物学假设证据方面的效用
Influencers
[V] Influence Flowers of Academic Entities [PDF]
本文呈现“影响力之花”,这是一个新的视觉隐喻,用于描述学术实体的影响力,包括人物、项目、机构、会议和期刊。虽然许多工具都对影响进行了量化,但本文的目标是暴露实体之间的影响流。“影响之花”是一个以自我为中心的图,查询实体位于中心。花瓣的样式反映了同类型或不同类型的其他实体之间的影响力。例如,人们可以通过研究主题来分解研究实验室的传入和传出影响。“影响力花”使用了微软学术图的最近快照,包括2.12亿作者,1.76亿出版物,12亿次引用。交互式网络应用“影响力地图”(Influence Map)就是围绕这个搜索和策划可视化的中心隐喻而构建的。本文还提出了一种可视化的比较方法,可以突出影响模式随时间的变化。团队通过几个案例研究证明,影响花支持以下数据驱动的调查:研究人员的职业生涯;论文和项目,包括那些被延迟承认的项目;研究机构的跨学科特征;以及会议上不断变化的话题趋势。通过对比研究人员的学术活动和Twitter活动,团队还将该工具用于学术引用以外的影响力数据。
[V] WeSeer: Visual Analysis for Better Information Cascade Prediction of WeChat Articles [PDF]
社交媒体,如Facebook和微信,使数百万用户能够以前所未有的规模创造、消费和传播在线信息。社交媒体上丰富的信息使得微信公职人员的竞争更加激烈——由于注意力的零和本质——吸引用户注意力的文章(即帖子)。因此,只有一小部分的信息会变得非常流行,而其余的信息会被忽视或者很快消失。这种典型的“长尾”现象在社交媒体中非常普遍。因此,近年来,人们对预测未来社交媒体帖子的流行趋势,了解影响帖子流行的因素越来越感兴趣。然而,现有的预测模型要么依赖繁琐的特征工程,要么依赖复杂的参数调整,难以理解和改进。
在本文中,团队研究并改进了一个基于点过程的预测模型,结合可视化推理支持用户与预测模型之间的通信,以获得更好的预测结果。该系统可帮助用户揭示模型背后的工作机制,并根据所获得的信息提高预测精度。团队使用真实的微信文章来证明该系统的有效性,并在大量微信文章中验证改进的模型。还总结了来自微信领域专家的反馈
[V] R-Map: A Map Metaphor for Visualizing Information Reposting Process in Social Media [PDF]
本文提出R-Map (repost Map),一种可视化的分析方法,使用地图隐喻来支持对社交媒体中信息转发过程的交互式探索和分析。一篇原创的社交媒体帖子会在网络上引发大量转发(也就是转发),涉及数千甚至数百万持不同意见的人。这种重发行为形成了重发树,其中节点表示消息,链接表示重发关系。在R-Map中,重发树结构可以用突出显示的关键角色和平铺节点来空间化。将虚拟地理空间中重要的转发行为、下列关系和语义关系分别表示为河流、路线和桥梁。R-Map支持使用语义对大量信息重发进行可伸缩的概述。在地图上提供额外的交互,以支持调查时间模式和用户在信息扩散过程中的行为。本文用两个用例和一个正式的用户研究来评估我们系统的可用性和有效性。
Color
[I] Estimating color-concept associations from image statistics [PDF]
为了在分类信息的形象化中解释颜色的意义,人们必须确定不同的颜色如何对应不同的概念。在视觉化中,当颜色和概念之间的分配符合人们的期望时,这个过程会更容易,使调色板在语义上具有可解释性。为了语义上的可解释性,人们已经在努力优化调色板设计,但是这需要对人类颜色概念的关联有很好的估计。从人那里获取这些数据是昂贵的,这促使了对自动化方法的需求。本文开发并评估了一种新的方法,以一种与人类评分强烈相关的方式自动估计颜色概念关联。基于之前使用谷歌的研究图像,本文的方法直接操作在谷歌图像搜索结果,不需要人工循环。具体地说,评估了几种提取图像原始像素内容的方法,以最佳地估计从人类评级中获得的颜色概念关联。最有效的颜色提取方法是在颜色空间中结合圆柱扇区和颜色类别。本文的方法仅使用一小组图像可以准确地估计出不同水果的平均人类颜色概念关联。这种方法还可以很好地概括为更复杂的、与回收相关的、可以以任何颜色出现的对象概念。
[S] Measuring and Modeling the Feature Detection Threshold Functions of Colormaps [PDF]
伪着色是科学可视化中最常用的技术之一。要对标量字段应用伪着色,每个点上的字段值将使用一系列颜色中的一种(称为色图)表示。生成色彩图的原则之一是均匀性,以前确定均匀性的主要方法是应用均匀色彩空间。
本文提出了一种新的评价彩色地图特征检测阈值函数的方法。该方法被用于众包研究中,用于直接评价三种特征尺寸的九种彩色地图。结果被用来测试一个假设,即统一颜色空间(CIELAB)将准确建模的彩色映射特征检测阈值相比,一个模型的色度成分权值减少。本文还验证了特征检测可以仅根据亮度进行预测的假设。结果否定了这两种假设,并且本文演示了当任务是在彩色映射数据中检测较小的特征,CIELAB颜色空间中绿红蓝黄项的权重减少,如何创建一个更准确的模型。该方法本身和改进后的CIELAB均可用于色彩图的设计和评价
[S] Measuring the Effects of Scalar and Spherical Colormaps on Ensembles of DMRI Tubes [PDF]
本文报告了在视觉化扩散磁共振成像(DMRI)管的集合标量和方向的颜色编码的经验研究结果。实验测试了用于平均分数各向异性(FA)任务(灰度、黑体、发散、等亮度-彩虹、扩展黑体和冷温)的6种标量颜色图,以及用于道路追踪任务(均匀灰度、绝对、特征图和Boy表面嵌入)的4种三维方向编码。结果表明,扩展黑体、冷暖黑体和黑体仍然是识别三维集合平均的最佳方法。等亮度-彩虹着色导致与其他颜色图相同的总体平均精度。尽管如此,超过50%的答案始终有更高的总体平均估计值,独立于平均值。色调影响均值的总体估计,而不是亮度。对于集合定向跟踪任务,作者发现,Boy表面嵌入(最大的空间分辨率和对比度)和绝对颜色(最低的空间分辨率和对比度)方案比特征图方案(中等分辨率和对比度)得到更准确的答案,在精度方面表现为可视化设计中的奇异谷现象
Searching & Querying
[I] Searching the Visual Style and Structure of D3 Visualizations [PDF]
本文为D3可视化提供了一个搜索引擎,允许基于其视觉风格和底层结构的查询。为了构建引擎,团队从网上抓取7860 D3可视化集合,并解构每个集合,以恢复其数据,其数据编码标记和描述数据如何映射到标记的可视属性的编码。团队还提取了标记的轴和其他非数据编码属性(如字体、背景颜色)。本文的搜索引擎将这种样式和结构信息以及有关包含图表的网页的元数据进行索引。本文展示了可视化开发人员如何搜索集合,以找到显示特定设计特征的可视化效果,从而探索可能的设计空间。还演示了研究人员如何使用搜索引擎来识别常用的视觉设计模式,并在收集的D3图表中执行这样的人口统计学设计分析。一项用户研究表明,可视化开发人员发现,与只允许在包含图表的网页上进行关键字搜索的基准搜索引擎相比,基于本文的风格和结构的搜索引擎在查找不同D3图表设计时更有用,更令人满意。
[V] A Natural-language-based Visual Query Approach of Uncertain Human Trajectories [PDF]
可视化查询是交互式探索海量轨迹数据的关键。然而,数据的不确定性给满足高级分析需求带来了深刻的挑战。一方面,很多基础数据并不包含精确的地理坐标,例如,手机的位置只是指手机所在的区域(即手机基站),而不是精确的GPS坐标。另一方面,领域专家和普通用户更喜欢用一种自然的方式来访问和分析大量的运动数据,例如使用自然语言句子。
本文提出了一种视觉分析方法,可以从文本句子中提取时空约束,并支持一种有效的查询方法,针对不确定的移动轨迹数据。该方法首先利用点向量及其覆盖区域的语义信息对大量空间不确定轨迹进行编码,然后利用有效的索引机制将轨迹文档存储在文本数据库中。可视化界面促进了大型轨迹数据的查询条件规范、位置感知可视化和语义探索。在真实人类移动数据集上的使用场景证明了本文方法的有效性。
[V] You can’t always sketch what you want: Understanding Sensemaking in Visual Query Systems [PDF]
可视化查询系统(VQSs)使用户能够以交互方式搜索具有所需可视化模式的折线图,通常使用直观的基于草图的界面指定。尽管过去的VQSs工作已经进行了几十年,但这些努力并没有转化为实践的采用,可能是因为VQSs在很大程度上是在不现实的实验室环境中进行评估的。为了弥补这种采用上的差距,作者团队与来自三个不同领域的专家合作——天文学、遗传学和材料科学——通过长达一年的以用户为中心的设计过程,开发了一个支持他们的工作流程和分析需求的VQS,并评估VQSs在实践中如何使用。研究结果表明,临时粗略查询并不像以前的工作建议的那样常用,因为分析师通常不能准确地表达他们感兴趣的模式。此外,本文还描述了增强的VQS支持的三种基本感知过程。团队发现参与者使用了所有三种过程,但比例不同,取决于每个领域的分析需求。研究结果表明,为了使未来的VQSs在更大范围的分析研究中有用,所有这三种感知过程都必须被整合起来。
[V] Do What I Mean, Not What I Say! Design Considerations for Supporting Intent and Context in Analytical Conversation [PDF]
自然语言是创建可视化和与可视化交互的一种有用的方式,但用户对自然语言系统的智能往往抱有不切实际的期望。用户期望和系统能力之间的鸿沟可能会导致令人失望的用户体验。因此,如果我们想要设计一个自然语言系统,围绕系统智能的需求是什么?
本文回顾了作者团队在Ask Data的设计中是如何回答这个问题的,Ask Data是一种自然语言交互功能画面。团队考察了影响感知系统智能的两个因素:系统理解输入话语背后的分析意图的能力和上下文解释话语的能力(即考虑当前的可视化状态和最近的动作)。本文的目标是理解系统需要以何种方式来支持智能的这两个方面,以实现积极的用户体验。首先描述一个预设计《绿野仙踪》的研究让团队对这个问题有了更深刻的认识,并缩小了所考虑的设计空间。然后,反思该研究对系统开发的影响,考察该研究的设计含义如何在实践中发挥作用。本文工作为视觉分析中的自然语言交互设计提供了见解,同时也反映了设计前实证研究在视觉分析系统开发中的价值
[V] TopicSifter: Interactive Search Space Reduction Through Targeted Topic Modeling [PDF]
主题建模通常用于分析和理解大型文档集合。然而,在实践中,用户希望关注特定的方面或“目标”,而不是整个语料库。例如,给定一个大的文档集合,用户可能只想要一个更小的子集,这个子集更符合他们的兴趣、任务和域。特别地,本文关注的是具有高查全率的大规模文档检索,其中任何丢失的相关文档都是至关重要的。
简单的关键字匹配搜索通常1)在研究数据集之前,很难找到能够覆盖感兴趣的文档的关键字查询列表,2)有些文件可能不包含感兴趣的确切关键字,但可能仍然高度相关,3)词具有多义性,这会导致检索到的子集中包含不相关的文档
本文提出了TopicSifter,一个用于交互式搜索空间缩减的可视化分析系统。该系统采用了基于非负矩阵分解的目标主题建模,并允许用户给出相关反馈,以细化目标,引导主题建模获得最相关的结果。
![支付宝]() 支付宝
支付宝