BarcodeTree:多层次结构的可伸缩比较
IEEE引用格式:G. Li et al., “BarcodeTree: Scalable Comparison of Multiple Hierarchies,” IEEE Trans. Vis. Comput. Graph., vol. 26, no. 1, pp. 1022–1032, 2020, doi: 10.1109/TVCG.2019.2934535.
摘要
本文提出了一种新的可视化技术BarcodeTree(BCT),用于比较多棵树的拓扑结构和节点属性值。BCT可以同时提供100个浅层且稳定的树的概览,而不需要聚合单个节点。每个BCT使用类似于条形码的样式在单行中显示,允许树垂直堆叠,匹配节点水平排列,以方便比较并保持空间效率。作者设计了一些视觉线索和交互技术来帮助用户理解树的拓扑结构和比较树。在两种BCT与icicle plots的比较实验中,结果表明BCT降低了不同树之间的垂直距离,使树之间的比较更加直观。本文还提供了两个案例研究,涉及数百棵树的数据集,以演示BCT的效用。
文章简介
数据集有时由许多相似的树(不同地方的图书馆)或随着时间变化的单个树组成(一个网站的网站地图),这种树集合的可视化概述可以极大地帮助执行比较,识别存在或者不存在的节点或子树,亦或是查找趋势和异常值
之前的许多文献都是单树可视化,少有树的可视化比较,大多局限于一次可视化两棵树,也有同时展示三棵树或者更多树的可视化,但是结果显示不超过40棵树,随着各种数据源的不断增长,越来越需要可视化更多的树
本文提出了BarcodeTree(BCT),用于跨多棵树对拓扑结构和节点属性值进行可伸缩的比较,BCT将每棵树线性化为单行,垂直压缩可视化,便于多棵树的堆叠和匹配节点的对齐,减少了匹配节点之间的距离,本文研究了两种变种,BCTw(宽度编码)和BCTh(高度编码),它们分别将节点深度编码为矩形的宽度或高度,及节点属性可以用颜色编码,或者(在BCTw的情况下)用矩形的高度编码。为了帮助用户理解拓扑结构,作者还设计了“结构提示”来突出显示光标下节点的后代、祖先和兄弟节点。

BCTs的设计是通过使用相对较浅和稳定的树数据集来实现的。所谓“稳定”,指的是有一个预定义的通用树,它是数据集中所有树的超级树,树之间的区别在于它们可能包含超级树中不同的节点子集和属性,每个节点上的值可能会改变。举一些这种树的数据集的例子:
- 一个大学图书馆的多日日常借阅记录,书遵循预先定义的分类系统
- 多个图书馆的藏书
- 不同政府或者同一政府多个部分的长期预算
- 电子商务网站产品分类层次随时间增长的层次结构
作者将两种BCT和icicle plots以及Indented Pixel Tree Plots (IPTP)进行研究比较,在所有研究任务中,花在IPTP上的时间都比icicle plots多,然后进行对照实验,比较BCTw、BCTh和icicle plots,发现BCTs在需要理解单个树拓扑的任务上花费的时间明显更多,而在比较多棵树的任务上花费的时间明显更少
本文的贡献有:
- BarcodeTree,一种新颖的可视化技术,用于比较多个浅层和稳定树的拓扑结构和节点属性值,可以容纳100棵树,每棵树有数百个节点(但扇出度较小),在正常屏幕尺寸范围内
- 视觉反馈(“结构线索”)帮助用户理解拓扑结构
- 一个RCT表明,BCTs可以使树比较任务比与之竞争的可视化技术更容易
- 两个涉及图书馆图书数据集的用例来演示BCTs的效用
相关工作
单树可视化
根据父节点-子节点关系的可视化编码,可以将树可视化分为显式和隐式技术,显式技术用可见的边,线段或弧对这些关系进行编码,隐式技术使用包含(例如,子节点嵌套或封闭在父节点内)或邻接
大多数显式的树形可视化在2D或3D空间中排列分层数据,而在1D空间中排列节点的研究还不够。Thread Arc按照时间顺序将树中的节点沿1D行排列,并在节点之间使用圆弧来编码父子关系。然而,在线弧中使用的弧使它很难压缩布局成一个薄条状,这将最终导致堆叠许多树在一起。相反,BCT不使用显式的视觉元素编码父子关系,这增加了堆叠多棵树的空间效率
在隐式树可视化中,包含编码的一个突出示例是treemap,子节点在父节点体内安营扎寨,通过大小来显示节点属性值,而非叶节点的属性值通常是其子节点的和。相比之下,BCTs允许节点的属性值独立于其子节点的值。树状图通常排列为2D或3D。ArcTree将分层数据线性化,并将节点排列在单行中,这可以看作是一个“一维”树图
邻接编码,比如冰柱图(icicle plots),是显式编码和包含编码之间的折中,与显式编码相比,使用邻接不显示节点之间的显式边缘,从而节省了空间,与树状图等包含编码相比,使用邻接并不那么节省空间,但使树的不同层次更容易区分,冰柱图显示了垂直邻接的父子关系:子节点位于父节点之下。树的每一层都是一行,而整棵树占据几行。虽然可以将多个冰柱图垂直堆叠起来进行树的比较,但BCTs比冰柱图需要更少的垂直空间。这样BCTs就减少了不同树的匹配节点之间的距离。
BCTs可以理解为另一种邻接编码。它以深度优先遍历的顺序将树的节点映射到双杠上。每个父节点既不包含子节点,也没有到子节点的显式链接,但是用户仍然可以识别底层的拓扑结构。这类似于缩进轮廓的布局(在许多文件浏览器中使用)和缩进像素树图(IPTP),这两种布局都按照深度优先遍历的顺序定位节点。缩进大纲布局很适合显示带有文本标签的节点。为了使用户能够阅读这些文本标签,缩进大纲总是将节点垂直排列而不是水平排列。如果从节点中删除文本标签,压缩并旋转90度,就可以得到一个类似于BCTh的布局,使其适合将多个树堆叠在一起。IPTP为树的每一层分配单独的行,就像icicle plots一样,因此这两种布局的垂直压缩程度都不如BCTs
树的可视化比较
比较是数据分析中必不可少的一项工作。有一系列技术可以用于可视化地比较树,本文将其细分为:并置(juxtaposition)、合并视图(merged views)和原子(atomic representations)表示。
并置是最普遍的策略,可以在空间或时间上进行。空间并置可以通过节点-链接表示,径向表示法和树状图来实现。这种并排视图可以通过刷屏、链接和动态查询来利用交互,交互式地突出显示其他树的相应节点。但是,如果没有交互,就很难理解许多节点突出显示的差异,这使得它无法向用户提供跨多颗树的许多更改的概览。此外,因为以前工作中的表示没有像BCTs中那样垂直压缩(也就是说,它们没有压缩),这些先前的技术无法扩展树的数量。之前的作品也将冰柱图并列比较。其中一些将两个冰柱图邻接排列,并用边连接匹配的叶节点。通过镜像冰柱图,代码流允许用户比较两棵以上的树。明确绘制的链接提供了拓扑结构差异的概述,但也占用了很大的空间,再次阻止了该技术一次容纳数量超过“少量的树”。Taxonaut将多个缩进轮廓水平并置,并使用联合树对它们进行对齐,但它的可伸缩性仍然不尽如人意,因为每个缩进的大纲需要占用几列。一些研究使用弯曲波段在树中连接匹配节点,但代价是将单个节点“模糊在一起”。时间并置,例如时间树,使用动画在不同的树之间转换,这种策略也不能很好地适用于大量的树木。用户记住帧之间变化的能力有限,因此必须多次查看动画
之前的一些作品建议将多棵树合并到一个单一的视觉表现中,以提高空间效率。Beck et al提出了一种依赖结构矩阵,该矩阵沿邻接矩阵的每边排列一个冰柱图,矩阵中的每个单元编码节点的差异。这种方法一次只能容纳两棵树,矩阵只显示叶子节点比较的结果。Graham et al通过将一些树合并成一个有向无环图(DAG)表示来探索这些树。与联合树相比,DAG允许显示一个节点的多个祖先路径。合并的视图需要显示多个树之间的差异。然而,多个树的关系是复杂的,尤其是在处理大量树时,而且在一个合并视图中显示这些结果也很困难
对于数量足够大的树,有限的屏幕空间无法显示所有树的全部细节,因此开发了将树可视化为原子表示的技术。之前的工作将每棵树可视化为散点图中的单个点,以支持对大量树的比较。两点之间的距离表示关联树之间的相似程度。TreeEvo主要关注家谱的结构异质性。它使用像素线可视化每个家族树,并将它们分组到Sankey图的节点中。关系的显式表示只显示来自高级概述的比较结果,但不能提供拓扑结构和节点属性值的详细比较。
尽管之前在树的比较方面做了大量的工作,但据我们所知,之前的方法还不能同时完整地显示100棵树,即在一个典型的PC屏幕上同时显示所有单个节点、拓扑结构和节点属性值。这是BCT的一个独特的特点
需求分析
本文寻求一种技术来比较多个浅层和稳定的树,这种技术比以前的技术更具可扩展性。首先考虑以前关于树比较的文献,以确定支持哪些任务。Guerra-G’omez et al确定了五种树形比较
- 比较节点没有属性值时的拓扑差异
- 比较拓扑结构没有变化的叶节点的属性值
- 比较拓扑结构没有变化的所有节点的属性值
- 比较叶节点的属性值与拓扑结构的变化
- 比较拓扑变化时所有节点的属性值
Munzner等人指出,结构比较是通过将一棵树上的每个节点与另一棵树上对应的节点相关联来实现的,除了比较任务,Chi等人还为多树探索确定了全局和局部任务,全局任务指的是比较多个树以发现趋势/模式。本地任务指查找有关拓扑或节点属性的特定信息。本文设法支持上述所有类型的任务。可以考虑的一些与树相关的附加任务是编辑树的方法(例如,移动节点或子树),但是这样的编辑任务超出了本文的范围,因为本文寻求可视化数据
因此,本文对新布局的需求来自三个主要需求。为了支持Guerra-G’omez的五个任务,需要一种技术,以一种能够实现高效比较的方式显示拓扑和节点属性,为了支持全局任务,该技术应该显示尽可能多的树,同时还应该显示每棵树中尽可能多的单个节点。为支持本地任务提供每个树的拓扑结构的清晰描述也是可取的。然而,与容纳许多树和许多节点相比,清晰的拓扑结构不那么重要。这是因为用户总是可以从使用新布局的许多树的概览开始,比较多个树并发现趋势或异常值,然后再向下钻取到一个或几个树,这些树使用更传统的布局来更清楚地显示拓扑。
以下是本文具体的设计要求。R1和R2解决全局任务的需要,R3和R4支持Guerra-G’omez等人确定的五种比较,R5支持本地任务
R1:在一个屏幕中显示许多树
在一个典型的显示空间中提供概述对于比较多个树是非常重要的,这也是树比较的许多使用场景的需求之一
R2:表示每棵树中的多个节点
可视化应该显示每个树中的单个节点。在用户仍在查看多树数据集的概述时提供这种细粒度的信息,减少了用户向下钻取更详细视图的需要
R3:为每个节点显示一个定量属性
对每个节点的属性值进行编码,以便能够跨树比较节点值,从而揭示趋势和异常值。
R4:便于在许多树中比较节点的存在/不存在或属性值
在多棵树中找到匹配的节点、比较它们的属性值以及比较不同树中节点的存在与否应该很容易
R5:显示每棵树中的拓扑(父-子)关系
它应该有可能辨别树数据的拓扑结构。最后列出这一要求是为了表明,如果为了提高空间效率而牺牲一些对父子关系清晰度的牺牲是可以接受的(R1,R2)
BarcodeTree设计
根据以上的设计要求,本文提出了BarcodeTree,BCT是一种比较多棵树之间拓扑结构和节点属性值的树形可视化方法。在本节中,将介绍BCT的可视化设计,然后提出交互技术来帮助用户理解底层的层次数据
视觉编码设计
为了实现树和节点数量的可扩展性,作者研究了多棵树到垂直和水平位置的映射拓扑。具体来说,BCT将每棵树可视化在单行中,以最小化其垂直范围,从而最大限度地增加可以垂直堆叠的树的数量(R1),BCT还在每行中水平地打包节点。父子关系以一种节省空间的方式编码到相对位置,以最大化可以水平打包的节点数量(R2)
BCT将每个节点表示为一个矩形,可以非常有效地呈现,这意味着可以以交互帧速率呈现大量节点(R1,R2),矩形的视觉通道(宽度,高度,颜色)可以编码节点深度和节点属性值(R3),将节点深度映射到矩形宽度产生BCTw。具体来说,根节点的宽度最大,深度越深的节点的宽度越小。BCTw中相邻节点的宽度差是相同的。将节点深度映射到矩形高度会产生BCTh,这使得用户更容易地感知每个节点的深度。在大量树的可视化结果中,每个节点只占用很小的空间以适应屏幕空间。具体来说,每个节点的宽度和高度都很小。较小的长度可以编码节点深度,因为目标层次化数据相对较浅。然而,节点属性值具有较高的动态范围。因此节点属性值只能编码为节点颜色,而不受节点大小的限制。将节点属性值编码到颜色通道中无法支持精确的比较。其余视觉通道(高度BCTw和宽度的BCTh)在某些情况下可以重复编码属性值作为补充。但是,将属性值编码到BCTh的节点宽度中,会导致对齐后节点之间的间隙增大,从而降低空间利用效率。因此,这种设计被排除。
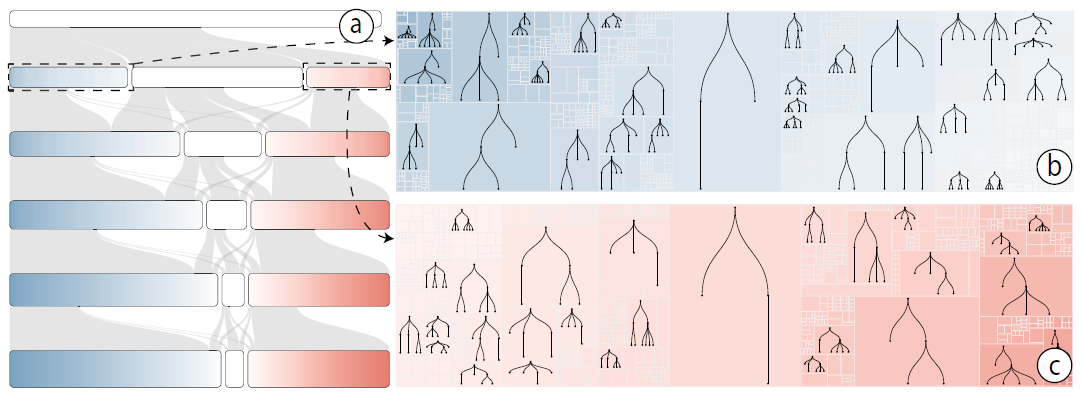
BCTs使用预先排序的深度优先遍历来确定水平节点的位置,它对父-子关系进行编码。根据第一次遍历时间的顺序,将层次结构中的节点从左到右添加到布局中。每个节点的后代被放置在节点的右侧。用户可以通过扫描N的右侧找到节点N的后代,直到遇到与N宽度或高度相同的另一个节点,这取决于使用的BCT的变体。因此,BCT允许用户解释树的拓扑结构(R5),由于它的紧凑性,BCT可以嵌入到单行文本中,就像火花线一样。例如,表示具有11个节点和4个级别的树。
交互设计
为了帮助用户理解和导航分层数据,本文为BCTs设计了三种交互技术。下面以BCTw作为一个例子来说明交互技术和这些设计也可以应用到BCTh
结构线索突出,尽管用户可以分辨出BCTs中的拓扑,但这个过程可能很繁琐,需要用户顺序地扫描节点。为了帮助理解(R5),本文添加了交互式结构线索。下图显示了如何使用下划线或标记来表示光标下节点的祖先、子节点和兄弟节点
为了表示后代,首先使用单个水平笔画(图a)。然而,发现分析人员仍然难以理解后代的特征,如子树的数量或平衡。因此,团队开发了图b中的变体,其中每个子树都用单独的水平笔画表示。笔画的数量和长度表示子树的数量和大小,便于判断树是否平衡
压缩与对角线条纹符号,对于具有数万个节点的树,BCTs表示可能非常宽,很难在屏幕中容纳。在探索大型层次数据时,用户通常只对少数子树感兴趣,其他部分会分散他们的注意力。如果几个感兴趣的子树不能在相同的屏幕空间中显示,用户需要水平地来回滚动以在这些子树之间导航。为了方便这种探索,用户可以选择感兴趣的子树,然后将每个连续的无兴趣区域聚合为对角条纹符号
折叠/展开节点,当一个分支中的节点不能在屏幕中显示时,它将阻碍用户的导航。本文提供了折叠/扩展交互,以最大限度地利用BCT可视化表示进行交互可视化,图中显示随着用户细化他们感兴趣的焦点而逐步打开分支的情况。压缩分支用等腰三角形预览。预览图标在压缩分支的根节点下面
三角形符号的视觉编码类似于Space-树,三角形底的宽度编码为平均宽度(项目数除以深度)。高度编码子树的深度。暗度编码子树的节点总数。即使是折叠的子树,用户仍然可以从三角形符号中获得概览信息,甚至可以对整个子树进行粗略的比较。单击节点可以打开折叠的分支
对齐比较法
为了比较多棵树之间的拓扑结构和节点属性值,本文提出了一种包含两个步骤的比对方法。第一步是垂直地并置多个树,第二步是水平地对齐BCTs。还介绍了对齐结果和排序交互的可视化编码
水平对齐,本文的方法对多个树进行对齐,并将匹配节点映射到相同的水平位置,以帮助用户比较它们的拓扑结构(R4)。本文的对齐方法构造了一个联合树,将多棵树合并成一棵树(见下图算法),然后用BCT对并集树进行可视化,得到并集BCT,并将每棵树中的节点映射到它们在并集BCT中的匹配节点的位置。并联BCT作为节点的一种超集,由多个节点组成。构造union BCT是一个自顶向下的递归过程。每次迭代合并所有匹配的子节点(及其子树),然后追加未匹配的子节点。映射策略确定每个节点的位置,允许在垂直叠加多棵树后将匹配节点放置在同一水平位置
由于对齐结果将多棵树的节点合并,因此对齐结果的宽度大于单个BCT。本文方法支持交互式地对齐一个节点子集,并将其他节点按原始BCT顺序排列,这减少了比较结果的宽度。本文方法提供了两种对齐策略,即对齐感兴趣的子树和将树对齐到某个级别。
图a显示了三个原始BCTs。本文方法通过根据是否需要对齐将BCTs划分为段来对齐感兴趣的子树。每个分区段包含一个子树,然后计算每个分段的最大长度,并首先对它们进行对齐。然后,本文方法分别计算每个片段中节点的布局。如图6(b)所示,对于未对齐的片段,基于BCT布局算法对节点进行布局。对于对齐后的节点,采用基于并集的对齐比较算法进行节点布局
为了将BCTs对齐到一定的级别,如图c所示,首先构建该级别以上节点的联合树,然后计算这些树的叶节点之间的后代节点的最大长度。然后将联合树的节点放置并保留空白空间,空白空间的长度为每个叶节点后面的最大长度。最后,计算节点在相应的空白空间中的对齐层下的位置。
视觉编码,对齐结果将不存在的节点编码为轮廓矩形,用户可以选择节点/子树作为引用,并识别其他树中多余的/缺失的部分。BCT的可视化编码便于用户理解差异。它将缺少的节点映射为红色矩形,将多余的节点映射为绿色矩形,如下图a所示。将节点属性值编码为高度可能很难在不同的树之间进行比较,特别是当它们的差异很小的时候,选择如图(b)所示的方式后,在匹配节点上添加指标,显示节点值的正负变化,指示符的位置与参考节点的节点值相同,其颜色表示正负差异(R4)*
排序,用户可以根据不同的标准交互地对多个BCTs进行排序,首先,用户可以选择感兴趣的子树,并根据节点数或拓扑结构相似性对多棵树进行排序。其次,用户可以选择根据所选节点的值对多棵树进行排序。为了揭示这些树的进化模式,用户可以根据它们的原始特征,例如时间顺序,对它们进行排序
实验
作者进行了一个控制实验来评估两种BCT变种在四种不同任务中的性能
技术选择
本文的目标是评估BCT的两个变种BCTw和BCTh,为了进行实验比较,本文考虑了哪些现有技术还允许多个树沿着垂直(y)轴堆叠,而每个树的节点沿着水平(x)轴打包,更准确地说,是考虑在深度优先遍历过程中,叶节点的x坐标单调增加的计数。这一标准意味着不考虑径向布局技术,以及包含技术,如树状图和嵌套圆
一个众所周知的沿着轴排列叶节点的技术是冰柱图,经典的节点链接布局技术通过连接带有线段的冰柱图中矩形的中心以及父-子关系也可以做到这一点。但是,与经典的节点链接布局相比,冰柱图中的矩形为标签提供了更多的空间,也更容易用鼠标进行选择。之前的研究曾用冰柱图来比较多棵树,虽然没有对齐
另一种候选技术是缩进像素树图(IPTP),每个节点分配一个唯一的x的位置(不仅仅是叶节点),允许堆叠树的匹配节点保持一致和比较,IPTP最初发布的形式以较小的大小呈现叶节点,但是这将阻碍叶节点上的属性显示,因此本文的实现绘制了相同大小的所有节点
对于每种技术,本文提出了两个问题:每个子节点是否在x轴上重叠其父节点(1),在y轴上重叠其父节点(2),对于冰柱图,这些问题的答案是(yes, no),也就是说,在x轴上有重叠,但在y轴上没有,在BCT中,答案是(no,yes)。对于IPTP,答案是(no,no),这两个问题中的每一个都提供了一种折衷,重叠节省了空间,但可能使区分节点更加困难。因此,最终选择对四种技术做出研究:BCTw, BCTh, ICICLE, IPTP
分析技术和假设
表中根据几个标准比较了这四种技术,第三行是关于垂直空间的要求。如果假设所有的技术都显示相同大小的叶节点,那么很明显,BCTh尤其是BCTw比其他技术节省了垂直空间,允许不同的树更紧密地堆叠在一起。第四行是关于节点的大小:冰柱导致更大的非叶节点,使它们更容易用鼠标选择,表中的最后两行是灰色的,因为本文的答案是试验性的和假设的,最后第二行表示哪种技术最擅长传递树的结构: 本文怀疑BCTh,尤其是BCTw在这里会受到影响
最后一行涉及多个树的比较。本文怀疑ICICLE不支持对不同树中的匹配节点进行简单的比较,因为匹配节点之间的间隔空间被其他节点填满,阻碍了寻找匹配节点。然而,IPTP为每个节点分配唯一的x位置,由于没有中间节点,便于比较不同树中的匹配节点。两种BCT技术也都为每个节点分配唯一的x位置,并且允许不同的树之间离的更近,使得比较更容易
表中的最后两行是本文试图通过实验来研究的。目的是确认BCT确实在比较匹配节点方面更好,并测试其他技术是否在帮助用户理解树的结构方面更好。本文提出以下假设:
- H1: 对于需要理解结构的任务,相比于ICICLE或IPTP,BCT需要更多的时间和/或导致更高的错误率
- H2: 对于需要比较多棵树的任务,BCT比ICICLE或IPTP需要更少的时间
- H3: 在需要比较多棵树的任务中,BCT导致的错误率与ICICLE或IPTP相当(即不比ICICLE或IPTP差)
实验任务
为了测试前面的假设,设计了四个任务,Task1和Task2需要用户理解单个树的结构,Task3和Task4需要比较多个树
Task1:查找后代节点
将显示一个树,其中突出显示一个节点N。用户必须找到N的第二个子节点的第二个子节点,然后单击该节点来完成任务
Task2:寻找最近的共同祖先
将显示一个树,其中突出显示了两个节点N1和N2。用户必须找到N1和N2最近的(最深的)共同祖先,并点击它。如果N1本身是N2的祖先,用户必须单击N1的父节点
Task3:不滚动的树比较
在屏幕空间内显示三棵树的对齐结果,垂直堆叠将匹配节点放置在同一水平位置,其中一棵树T1突出显示为“参考树”。用户必须对这两棵树进行比较,以便在其他两棵树中找出哪一棵(称为T2)与参考树T1包含的相同节点最多。用户必须单击T2的标签才能完成任务。请注意,此任务不涉及单击节点,而是单击整个树的标签,而且无论使用何种树布局技术,这些标签的大小总是相同的。
Task4:与滚动的树比较
这与Task3相同,除了现在有6棵树要比较,而且在屏幕空间内一次只能看到3棵树,需要用户垂直滚动才能比较这些树,滚动是用鼠标滚轮完成的(也就是说,用户不需要点击滚动条来开始滚动)。要完成此任务,用户必须单击5个非引用树之一的标签,以指示哪个与引用树具有最多的相同节点
Task1和Task2的目的是检验假设H1,Task3和Task4度量了在多个树之间比较节点集以测试H2和H3的能力。Task3和Task4被设计用来衡量节省垂直空间的好处,特别是Task4,在Task4中,ICICLE和IPTP需要用户滚动更多的页面
Task1至4都在其它研究中有相似的内容 (具体文献说明看原文)
对于所有任务,节点的最大垂直大小始终设置为相同,相邻节点之间的水平间距也相同,此外,在BCTh和冰柱技术中,叶节宽度始终相同。但是在BCTw中叶子节点更薄,因为BCTw要求有薄的叶子节点来允许非叶子节点的宽度范围
本文的任务不需要用户比较不同节点之间的属性值。这是因为之前的工作已经研究了用不同通道编码的成对属性的比较。相反,文本感兴趣的是理解使用时的权衡,用BCT了解树结构和比较多棵树
初步研究
一项初步研究将所有四种技术(BCTw、BCTh、ICICLE和IPTP)与四名用户和所有四项任务进行了比较。用户来自计算机科学系。试点的目的是验证实验设计是否合适。在试验期间,每个用户花费了1.5个多小时来完成所有任务。试验的主要结果是,在所有任务中,IPTP总是比ICICLE慢。在试点之前,团队怀疑IPTP可以比ICICLE受益,因为在匹配节点之间没有任何节点。然而,在访谈中,用户报告节点占据间隔空间(以冰柱形式)并不妨碍比较;相反,它们提供引用来帮助查找其他树中的匹配节点。根据测量的时间和访谈结果,团队将IPTP从整个实验中移除,让整个实验中的用户在1小时内完成所有任务。
完整实验
为了了解BCT的优缺点,本文对BCTw、BCTh和冰柱进行了完整的对比实验
21名用户(年龄在25-35岁之间),来自计算机科学,经济,商业和金融领域,都是右撇子,熟悉层次数据,并对视觉分析任务有经验
任务在安静的戴尔精密计算机实验室中完成,T5500台式电脑,因特尔Xeon四核处理器,8GB,RAM和NVidia Quadro 2000图形卡驱动,23英寸LCD,1920x1080像素监控,实验平台用node.js和javascript开发
本文使用算法生成的数据,而不是真实世界的数据,这样可以更容易地控制数据的特征,使将来更容易复制类似的研究(如果需要的话),并避免使用任何特定的真实世界数据集可能带来的偏差
除Task4外,实验中生成的树都适合屏幕,不会滚动,深度在2到5之间,每个节点有0到5个子节点,同一组树之间的差异设计节点出现或消失,但不涉及节点从树的一个位置移动到另一个位置
BCT布局可以通过在对齐结果中复制每个移位的节点来显示节点的位移。然而,实验生成的数据并没有涉及节点位移,原因有二
- 为了节省垂直空间,实验中没有一种技术使用显式链接来显示树之间的匹配节点。因此,为了显示节点位移,所有技术使用节点重复是合理的。此外,这四种技术都以相同的深度优先顺序为叶节点分配x坐标。这些相似之处表明,当使用涉及节点位移的数据时,所有的技术都会遇到类似的问题,而为实验生成这样的数据可能只会延长试验时间和/或降低统计能力。
- 用于原型定性评估的真实数据集是基于图书馆图书分类的,其中节点从不从一个地方移动到另一个地方。这至少是真实世界中不发生节点位移的一个领域。
每个用户使用三种技术中的每种技术完成所有四项任务。任务按照固定的顺序完成。在每个任务中,用户以平衡的顺序分别经历了这三种技术,从热身试验开始。
总共有21个用户,4个任务,3个技术,8次重复= 2016次试验
用户被要求尽可能准确和快速地完成每次试验,并被告知准确性和完成时间同样重要
用重复测量方差分析来分析每个任务的速度和错误率
- 任务1中,ICICLE比BCT技术的每一种都要快得多,而两种BCT技术没有明显差异,方差分析发现这些技术的错误率之间没有显著差异
- 任务2中,技术有重大影响,冰柱图明显比较快,冰柱图的错误率显著低于BCT
- 任务3中,ICICLE比两种BCT技术都要慢得多,且两种BCT技术没有显著差异,错误率也没有显著差异
- 任务4中,ICICLE比两种BCT技术都要慢,错误率没有显著差异
鉴于初步研究的结果删除IPTP的考虑,重新表述假设如下:
- Task1和Task2中,BCT技术需要的时间比冰柱多
- 对于Task3和Task4,BCT技术需要的时间明显少于ICICLE
- 对于Task3和Task4, BCT技术的错误率并不比ICICLE差多少
所有三个假设都得到了证实
正如预期的那样,BCT技术完成拓扑解释任务更困难,但是树比较任务更简单
然后作者提到,Task1和Task2中的点击选择,都是对于节点来说的,移动鼠标光标和单击所需的时间由Fitts定律控制,较小的目标点击需要更多的时间,而ICICLE的非叶节点比BCT要大得多,因此是具备巨大的优势的,所以ICICLE在任务一二中优秀的速度并不奇怪,同时也说明,BCT的拓扑解释能力其实也并不像数据显示的那么糟糕
BCTh比BCTw速度更快且错误率更低,因为BCTh的设计旨在使每个节点的深度更清晰,然而,这种设计的代价是使BCTh的垂直可压缩性低于BCTw,这也意味着节点属性值只能使用颜色来显示,这比使用高度来表示数量值的效果要差
定性评估
本文通过与两位领域专家一起工作确定的两个用例来演示BCT技术的效用
数据集
本文的评估使用了大学图书馆的借书记录,图书馆经常根据杜威十进制分类法组织图书,这是一种专有的层次系统,树的更深层次对书籍进行分类,并不断改进,根节点包含所有的书籍,其中子节点对应文学,技术,社会,法学等分支,每个叶节点代表最细粒度的图书类别
数据集包含了两年的借书记录(01/01/2016 31/12/2017)。对于每一天,根据所有借书的Dewey decimal分类法构造一棵树,其中每个节点的属性值等于该节点所属类别的借书数量。数据集包含730棵树,每天一棵
原型
本文实现了一个基于BCT技术的原型系统。在这个系统中,顶部的柱状图显示了每天的借书总数(根节点上的属性值)。用户可以在直方图中选择间隔。在条形图的下面,交互式视图支持多重比较这两个部门。还实现了之前提出的交互技术,包括结构提示、对角条纹符号和节点对齐。系统还提供了数据挖掘的辅助功能,包括过滤和排序
专家用户
团队邀请了两位至少有15年经验的大学图书馆员来评估本文的基于BCT的多棵树的比较原型系统。两位专家感兴趣的是通过比较不同时期的借阅记录来优化人力资源配置和图书管理。在对数据集进行研究之前,专家们对原型系统的使用情况进行了简要介绍。下面是在他们的探索中出现的两个用例。第一种情况表明BCTs可以支持比较多棵树的拓扑结构,第二种情况表明
BCTs可以支持比较节点属性值
探究了一年中两个学期借书模式的差异
从总体直方图中,专家们了解到借书的数量是相似的。选择的树被可视化为BCT行,并垂直堆叠以供比较。
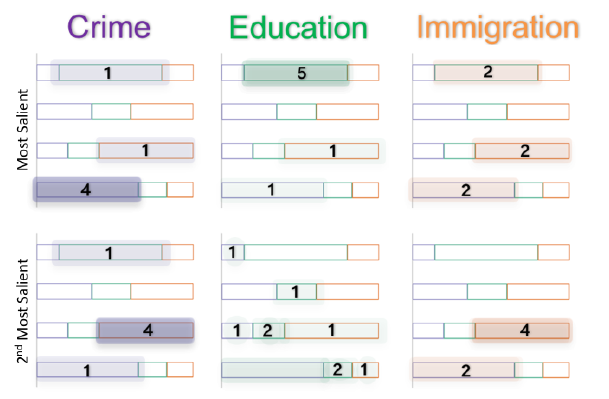
专家们在第二层对子树进行对齐,将匹配节点放置在相同的水平位置。他们发现,第一个时期的语言类别的借书数量比第二个时期的要多得多。然后,专家们将重点放在语言类别上,用对角线条纹符号压缩其他部分,并对齐语言范畴。图底部的探索结果显示了不同的拓扑变化模式
首先,在概述层面,专家们发现,在(a)区间内,学生借阅语言类图书的频率要高于(b)区间内,专家们还注意到,在两个区间内,类英语和古英语的拓扑结构变化都很小。具体来说,这类借阅记录几乎每天都有。但是,区间(a)中的语言和希腊语言这两类语言的借用模式与区间(b)中的借用模式有很大的不同。此外,专家们继续比较不同时期的借记所构建的拓扑结构。专家们发现学生们在周末通常不借阅语言范畴的书,在区间(b)的语言分类下,他们发现学生通常在周一借书
在查阅了大学手册后,专家们发现许多国际学生的基础课程都在第一学期。因此,与语言类相关的书籍在第一学期更受欢迎。从详细的借阅记录中,专家们还发现,国际学生借阅语言类图书最多。有了这个发现,图书管理员可以将语言类别下的图书位置更改到更方便的位置,并增加更多的管理员和志愿者来帮助留学生找到这些书
探讨了学生学期借用行为与假期借用行为的差异
专家们希望找到不同类别的节点属性变化规律,首先梳理了两个学期的概览直方图、区间,然后,专家们从比较结果概述开始探索
原型系统根据该类别下的借阅记录数量与借阅记录总数的比率提供过滤交互。由于专家希望探索最常借用的类别,他们将比率设置在0:35到0:95之间
可视化结果显示,在区间(c)中,社会科学与技术几乎每天都有大量的图书借阅(cs和ct)。在(a)区间,专家们发现社会科学类(as)的借阅记录数量呈上升趋势。具体来说,一开始会过滤掉更少的节点,然后随着时间的推移会出现更多的节点。但科技类借用纪录(at)保持稳定。在区间(b)期间,社会科学类的借书记录数量较多,而技术类的借书记录数量较少。此外,专家还发现中间出现两次异常增长。
手册上指出,大学提供了许多选修科目在间隔(b)从不同的系。学生需要选择感兴趣的课程并计入学分。然后,专家们调查了社会科学与技术相关课程的详细信息。社会科学有17门课,其中11门课在课堂上讲授。然而,与技术相关的学生在课堂上只有5门课程,其他16门课程涉及到行业实践和实习。在大学里只有需要上课的课程需要学生从图书馆借书。这样一来,学生更有可能选择社会科学相关的课程,而不是技术相关的课程。如上所述,(a)和(b)间隔的课程安排有很大差异,但(a)和(c)间隔的课程在社会科学与技术之间没有显著差异
专家反馈
团队与这两位领域专家进行了45分钟的一对一访谈,以收集关于技术的反馈。团队请专家使用原型自行探索。在这个过程中,回答他们的问题,并记录他们的评论和喜好。两位专家都表达了对使用BCT的热情。“BCT技术一开始有点难以理解,但它很容易学习和使用” (E1),“它提供了交互式工具,帮助我充分自信地探索数据” (E2)。E1和E2也证实了本文的搜索策略和交互建议可以帮助他们识别变异模式。E2是图书馆的一名技术人员,他认为BCT技术是节省空间的好方法,可以使多棵树垂直堆放。“具有交互式辅助工具的原型系统可以帮助决策者预测、准备和跟踪未来行为” (E1),他们一致认为BCT技术可以很容易地应用于其他涉及多个树的分析任务
结论与未来方向
本文介绍了BarcodeTree,这是第一个用于多个浅层和稳定树的可视化技术,它能够比较单一屏幕上100棵树的拓扑结构和节点属性值。本文实验证明了,BCT在理解单个树的拓扑结构(Task1和Task2)上需要比ICICLE多得多的时间,而在比较多个树的拓扑结构(Task3和Task4)上需要比ICICLE多得多的时间。此外,还通过案例研究演示了BCT的效用,这些案例研究包含数百棵树。
未来的工作可以设计一种方法,在BCT概述和其他树形可视化之间轻松切换,使拓扑更容易理解,并结合两种方法的最佳效果,实验结果还表明,BCTh变体比BCTw更容易理解拓扑,但代价是垂直可压缩性不如BCTw。未来的工作可以设计一种方法在这两种变体之间平滑的动画,允许用户根据当前的需要过渡到其中一种或另一种
BCT的一些限制是,如果某些节点具有较大的扇出(fan-out),那么BCT的可读性就会降低,而且BCT不是为比较每个节点都具有大量节点的少量树而设计的。这也可以在今后的工作中加以解决
树比较需要将一个树中的每个节点与另一个树中的匹配节点相关联。但是,本文工作并没有集中在匹配算法上,而是假设层次数据中的每个节点都有一个唯一的键,所以在多棵树中具有相同键的节点可以在线性时间内完全匹配,TreeJuxtaposer则通过两两相似度评分来计算最佳对应节点,这需要二次的计算时间。对于树匹配算法的研究还有待深入
在本文的视觉设计中,对角线条纹纹理的符号不能准确反映节点数,但设计它们是为了减少上下文的宽度,帮助用户关注子树。它们还可以为用户提供提示以支持进一步的探索。当可视化一个非常深的树或压缩,值得注意的是,相邻层节点间的宽度/高度差很小,用户可能难以识别拓扑结构。在这些情况下,允许用户选择给定的粒度级别并交互地更新宽度/高度。该方法支持对数值节点值进行编码,并在多个层次数据之间进行比较。未来的工作可以研究多树上多变量属性的比较
本文方法向用户提供了在屏幕空间中可视化多个树的概述。从概览中,用户还可以了解到每个节点的详细信息。然而,用户可能会被这些信息搞得不知所措,并发现难以探索。在未来,作者计划探索基于BCT对齐结果的自动模式检测算法,以方便用户的探索。
![支付宝]() 支付宝
支付宝