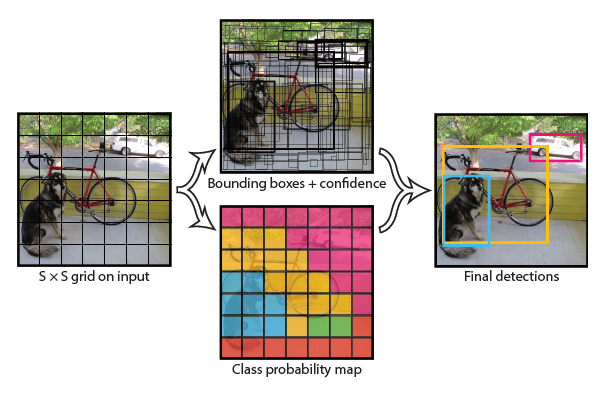
YOLOv2:全面升级的YOLO
YOLOv2多方面地对YOLO进行了优化,将算法的速度和精度都提高到了一个新的高度
YOLOv2沿用了YOLO的结构,并做了大量的优化
更精准 [Better]
YOLO相比于Fast R-CNN来说存在大量的定位误差,且召回率较低,因此优化主要是为了解决这两个问题
批标准化
YOLOv2用BN层代替了dropout,置于每个卷积层之后,有助于解决bp中梯度弥散和梯度爆炸的情况,mAP提升2%以上
高分辨率分类器
先在ImageNet上以$448\times 448$分辨率进行10个epoch的微调,然后根据检测结果对网络微调,这本质上是一种迁移学习,这种方法提升了将近4%的mAP
带锚框的卷积
YOLOv2移除了YOLO中的FC层,采用锚框来预测bbox,同时,将网络的输入从$448\times 448$缩小到416,这样特征图有奇数个位置,只有一个中心单元 (因为大型物体往往在图像中心),32倍下采样之后得到$13 \times 13$的特征图
同时,解耦类的预测和空间位置,区别于YOLO中为每个格子预测类别,YOLOv2为每个锚框预测类和对象
引入锚框后mAP从69.5下降到69.2,但是Recall从81%上升至88%
聚类提取锚框尺寸
若手工设计锚框的尺寸 (Faster R-CNN),就需要通过网络学习来对其进行调整,如果给定的先验框更好,网络就更容易学习到好的检测方法
基于这个想法,YOLOv2采用k-means聚类的方法来替代手工设计锚框,锚框的中心即网格的中心,采用欧式距离的话,较大的box会比较小的box产生更多的误差,因此采用如下式子表示距离
$d(box,centroid)=1-IoU(box,centroid)$
对速度和召回率之间做了一个权衡之后,确定k=5

偏移公式优化
在Faster RCNN中,偏移修正公式如下所示
$x=t_x * w_a - x_a$
$y=t_y * h_a - y_a$
$x_a$和$y_a$是锚框的中心点坐标,$w$和$h$是锚框的宽和高,t则是需要学习的参数,由于$t_x$和$t_y$是没有被约束的,所以预测框的中心会乱飘,所以训练的早期非常不稳定
因此yolov2采用了下列预测公式
$c$表示中心点所处区域左上角格子的中心点坐标,$p$代表锚框的信息,$\sigma$代表预测框中心点和左上角坐标的距离,通过$c$和$\sigma$得到预测框中心点坐标
细粒度检测
YOLOv2通过采用passthrough层来实现细粒度检测,这个东西和resnet中的shortcut类似,思想都是将高层的语义和低层的位置信息结合,无非是结合方式不同
passthrough采取的方式是把低层特征图一拆四 (如上图),然后和高层特征图直接叠加作为特征图
更快 [Faster]
YOLOv2不再使用VGGnet而是提出了Darknet-19 (19conv+5maxpooling)
Darknet-19的精度和VGG-16五五开,但是浮点运算量减少到约$\frac{1}{5}$
更强 [Stronger]
作者还构建了WordTree,一通操作之后可以识别9000种物体(YOLO9000),详见论文 (
![支付宝]() 支付宝
支付宝