ReGAT [多类型图结构]
Introduction
现有的达到SOTA的VQA系统大部分致力于学习图片和问题的多态联合表示,框架通常为:CNN识别图片区域+RNN编码问题+图片每个区域和问题做联合表示+分类器,这个框架被证明在VQA上是比较有效的
但是图片和自然语言之间仍存在语义鸿沟,比如给定一张斑马的照片,模型可能可以识别黑白像素,但是不知道哪个黑白像素是来自哪只斑马,那么这就使得诸如”最右边的斑马是小斑马吗”以及”所有的斑马都在吃草嘛”这类问题很难被回答,VQA系统不仅需要在图片和语言中识别目标(zebras)和周围的环境(grass),还要理解动作的语义(eating)和位置(at the far right)
这一类的信息需要模型超越单纯的目标检测,学习图像中视觉场景更整体的信息,一个方向是学习目标之间的位置关系(motorcycle-nextto-car),另一个方向是学习目标之间的依赖关系(girl-eating-cake)
基于这个观点,作者提出了Relation-aware Graph Attention Network (ReGAT),用一种新的关系编码器来捕获目标之间的关系。这些视觉特征代表了图像中更细粒度的视觉信息,提供了更为整体的场景解释,对回答复杂语义的问题有所帮助。出于对图像场景和问题类型的高差异的考虑,关系编码器学习了显性 (如空间/位置、语义/可操作) 关系和隐性关系,其中图像以图结构表示,通过图注意机制捕获对象之间的关系
此外,图注意是基于问题来学习的,在关系编码阶段可以通过问题注入语义信息,这样,关系编码器学习到的特征不仅捕捉了图像中对象交互的视觉内容,而且结合了问题中的语义线索,动态关注每个问题的特定关系类型和实例

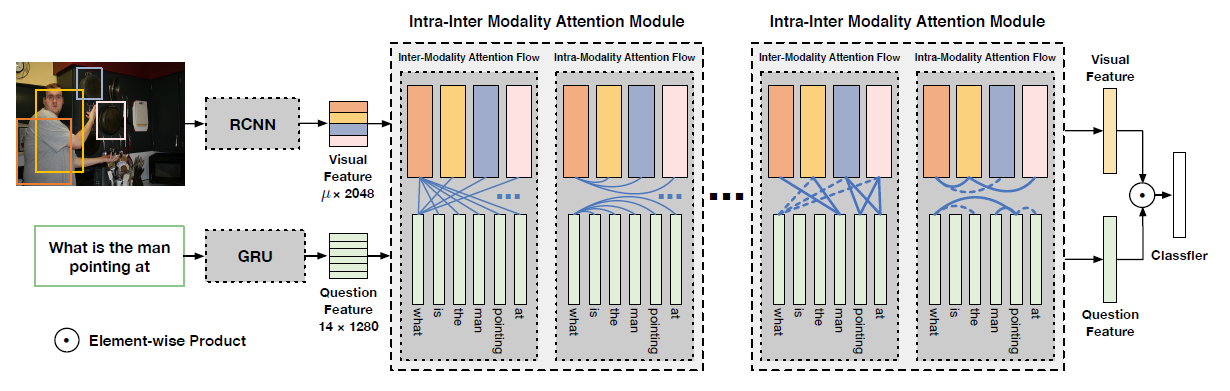
模型的整体框架如图,首先用Faster R-CNN来生成目标候选区域集,用一个问题编码器得到问题嵌入,接着每个区域的bbox和卷积特征被注入到关系编码器中,从图像中学习能感知关系、问题自适应、区域级别的表示,最后这些能感知关系的视觉特征和问题嵌入被输入到多模式融合模块中生成联合表示,该联合表示用于答案预测模块以生成答案
不同于以往的VQA系统,这篇文章的模型提出了一个新的维度:使用问题自适应的对象间关系来丰富图像表示,以提高VQA的性能
文章的贡献如下:
提出了一个基于图的关系编码器,通过图注意网络学习视觉对象之间的显性和隐性关系
学习到的关系是问题自适应的,可以动态捕获与每个问题最相关的视觉对象关系
ReGAT model能够在VQA 2.0中提高SOTA VQA模型,并且作者提出的模型在VQA-CP v2中达到了SOTA
Related Work
Visual Question Answering
目前VQA系统的主流框架包括图片编码器,问题编码器,多模态融合和答案预测器,近期的一些研究在图像方面探索了各种图像注意机制来定位与问题相关的区域,而在问题表达方面,有研究提出在编码阶段融合视觉和文本信息,协同问题引导图像注意力和图像引导问题注意力,还有研究探索了更高阶的融合方法,更好地结合文本信息和视觉信息(比如用双线性池化方法替代简单的元素点积,矩阵拼接,相乘等)
为了使模型更具有解释性,一些文献探索了图像更高层的语义信息,比如属性,标签和视觉常识,这些方法大多采用VQA-independent模型从图像中提取语义知识,R-VQA中提出了relationship-vqa数据集,直接挖掘基于vqa的关系事实,以向模型提供额外的语义信息,也有一些研究了如何利用记忆来辅助推理步骤,特别是对于困难的问题
然而,记忆或高级语义信息所带来的语义知识通常都被转换为文本表示,而不是直接作为视觉表示,视觉表示包含着关于图像的更丰富、更有指示性的信息。作者将对象关系直接编码到图像表示中,关系编码步骤是通用的,可以结合到任何VQA模型中
Visual Relationship
视觉关系在深度学习流行起来之前就被广泛研究过,早期工作将目标关系作为目标检测的后处理步骤,对于检测到的目标进行重打分,之前的一些研究也探讨了空间关系对改善图像分割的作用
视觉关系在很多计算机视觉任务上起到了关键的作用,它辅助了图像字幕的认知任务,改善了图像搜索和目标定位。近期视觉关系的研究更多地关注非空间关系,或是说语义关系,一些神经网络结构已经被设计用于视觉关系预测任务
Relational Reasoning
作者将前文提到的视觉关系定义为显性关系,这种关系对图像字幕任务非常有帮助,可以根据这些关系构建图结构,用图卷积网络来学习目标表示
另一个研究方向是隐性关系,即没有明确的语义或空间关系被用来构造图,所有的关系都隐式地由注意模块或通过输入图像的全连通图这种高阶方法捕获,比如通过使用简单的MLP对图像中所有可能的对象对进行推理,或是双线性融合方式
此外,还有一些研究提出了图像的问题导向图表示,Conditioned Graph Structures提出了一种图学习模型,采用了基于关系对的注意力和空间图卷积,Graph-Structured Representations探索了结构化的问题表示方式,比如解析树,利用GRU对对象和语之间的上下文化交互进行建模,Neighbourhood Watch引入了一个类间/类内边定义的稀疏图,通过语言引导的图注意机制隐式学习其中的关系
然而,所有这些工作无一例外关注在隐性关系上,这比显性关系更难解释
ReGAT同时考虑了显性和隐性的关系来丰富图像的信息,对于显性关系,使用Graph Attention Network(GAT)而非简单的GCN,GAT的优势在于可以为领域节点分配不同的重要度,对于隐式关系,模型学习了一个图,该图通过过滤掉与问题无关的关系来适应每个问题,而不是平等地对待所有的关系,作者进行了消融实验来验证了每个模块的重要性
Relation-aware Graph Attention Network
VQA任务可以被定义为给定一个图片对应的问题,目标是预测GT的一个最佳匹配,VQA文献中常见的做法是,将其视为一个分类问题:
前文的模型结构图中已经详细地给出了模型的结构,模型包含了一个图片编码器,问题编码器和一个关系编码器,图片编码器中使用了Faster R-CNN来识别目标集,每个目标包含一个2048维的特征和一个表示目标位置的4维bbox,问题编码器中使用GRU和自注意力来产生1024维的问题嵌入,下文将详细介绍关系编码器
Graph Construction
Fully-connected Relation Graph
通过将图像中的每个对象$v_i$视为一个顶点,可以构造一个全连通的无向图,每条边代表了两个对象之间的隐式关系,可以通过图注意力分配给每条边的可学习权值来体现,所有权值都是隐式学习的,不需要任何的先验知识,作者将建立这个图结构上的关系编码器称为隐式关系编码器 (implicit relation encoder)
Pruned Graph with Prior Knowledge
如果顶点之间存在显式关系,则可以通过修剪不存在相应显式关系的边,将全连通图转换为显式关系图,对于每对对象$i$和$j$,如果$
这些特征的显式本质要求预训练的分类器以离散标签的形式提取关系,在这张裁剪过的图上可以学习到不同种类的显式关系,作者探索了空间结构图和语义图
Spatial Graph
设$spa_{i,j}=
Semantic Graph
为了构造语义图,需要提取对象之间的语义关系,这可以通过在一个可视的关系数据集上训练一个语义关系分类器来表示为一个分类任务,给定两个对象区域$i$和$j$,目标是确定哪个谓词$p$来表示这两个区域之间的语义关系,语义关系的边是不对称的,比如$
分类模型的输入包含三个部分,主语区域$v_i$,宾语区域$v_j$和区域级特征向量$v_{i,j}$同时包含$i$和$j$,这三种特征都是从预训练的目标检测模型中得到的,然后通过嵌入层进行变换,将特征嵌入拼接并馈入分类层产生14个类的$softmax$分数,然后用训练好的分类器来预测给定图像中任意一对目标区域之间的关系
Relation Encoder
Question-adaptive Graph Attention
关系编码器用于动态编码目标之间的关系,在VQA任务中不同类型的问题可能会对应不同的关系,因此,在设计关系编码器时,作者使用问题自适应注意机制,从将问题中的语义信息注入到关系图中,动态地赋予与每个问题最相关的关系较高的权值
首先将问题特征和视觉嵌入连接
然后在顶点上做自注意,生成隐式关系特征,采用的注意力机制如下
对于不同类型的关系图,注意力系数$a_{ij}$,投影矩阵$W$以及邻域$N_i$的定义各不相同,$\sigma(\cdot)$是一个非线性函数
为了稳定自注意的过程,作者扩展了图注意力机制,采用了多头注意力(multi-head attention),执行了M个独立的注意力机制,并将输出的特征连接
Implicit Relation
学习隐式关系的图是全连接的,所以$N_i$包含了图中所有的目标,包括$i$自己,在Relation Networks的启发下,作者设计了一种注意力权重同时考虑了图像区域特征权重$a^v$和bbox的权重$a^b$
其中,$a^v$代表了图像区域之间的相似性,通过离散点积计算
其中$U,V \in R^{d_h \times (d_v+d_q)}$是投影矩阵
$a^b$则代表了空间位置关系
$f_b(\cdot,\cdot)$首先计算了4维的相对空间关系
$(log(\frac{|x_i-x_j|}{w_i}),log(\frac{|y_i-y_j|}{h_i}),log(\frac{w_j}{w_i}),log(\frac{h_j}{h_i}))$
然后通过计算不同波长的余弦和正弦函数将其嵌入到$d_h$维度的特征
$w\in R^{d_h}$将$d_h$维特征转换为标量,在$0$处进行裁剪,隐式关系的限制是通过$w$和0-裁剪操作来学习的
Explicit Relation
因为语义图中的边包含标签信息并且具有方向性,所以作者设计了一个对方向和标签敏感的注意力机制
$W_{(\cdot)}$和$V_{(\cdot)}$是矩阵,$b_{(\cdot)},c_{(\cdot)}$是偏移量,$dir(i,j)$根据边的方向选择对应的矩阵,$lab(i,j)$表示每条边的标签,当对所有区域${v_i’}_{i=1}^k$用图注意力机制编码后,区域级特征${v_i^*}_{i=1}^k$就被赋予了先验语义关系
与图卷积网络不同,该图注意机制有效地为相同邻域的节点分配不同的重要度,结合问题自适应机制,习得的注意权值可以反映哪些关系与特定问题相关,关系编码器可以以相同的方式在空间图上工作,只需要学习不同的参数集,细节省略不表
Multimodal Fusion and Answer Prediction
获得关系感知的视觉特征之后,采用多态融合策略将每个视觉特征和问题信息融合,文中提出的关系编码器保持了视觉特征的维数,可以与任何现有的多模态融合方法结合来学习联合表示
f是多态融合方法,$\theta$是可学习参数
答案预测器采用了两层的MLP,损失函数为二元交叉熵,在训练阶段,对不同关系的编码器进行独立训练,在推理阶段,将三个图注意网络 (semantic, spatial, implicit) 与预测答案分布的加权和相结合,$\alpha$和$\beta$是均衡超参数 ($0 \le\alpha+\beta\le 1, 0 < \alpha,\beta < 1$)
Experiments
消融实验
在VQA2.0上和SOTA的比较
可视化
![支付宝]() 支付宝
支付宝