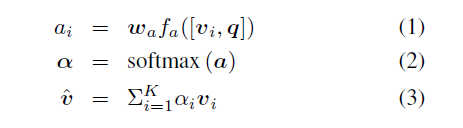DFAF [动态模内模间注意流]
VQA模型性能的提升得益于三个方面,一是更好的视觉和语言特征表示,二是注意力机制,三是更好的多模态融合方法
目前的VQA模型大多在学习视觉和语言特征之间的跨模态关系(inter-modality relations),Bilinear feature fusion主要通过特征的外积来获取语言和视觉模式之间的高阶关系,Co-attention和bilinear attentionbased
approaches通过学习词区域对(word-region pairs)之间的跨模态关系来完成VQA任务
此外也有学习模态内部关系(intra-modality relations)的方法,Hu et al提出探索模内对象-对象关系,以提高目标检测精度,Yao et al学习模内对象-对象关系,以提高图像字幕性能,BERT采用自注意机制对模内词关系进行建模,得到了SOTA的word embedding,
在解决VQA问题的框架中从未同时研究过模内关系和跨模关系,作者认为被大多数VQA系统忽略的模内关系是跨模关系的补充,每个图像区域不仅要从问题中的关联词/短语中获取信息,还要从相关图像区域中获取信息来推断问题的答案,这种情况要求一个统一的框架来为模间和模内信息流建模
作者提出了一个新的框架Dynamic Fusion with Intra- and Inter-modality Attention Flow(DFAF),目的是高效完成多模态特征融合,准确回答视觉问题,DFAF集成了跨模态的self-attention和co-attention在图像和语言之间实现信息的有效流动
DFAF框架首先生成中间注意流(intermodality attention flow, InterMAF),在图像和语言之间传递信息,InterMAF会生成视觉和语言的co-attention矩阵,每个视觉区域会根据该矩阵选择问题特征,反之亦然(vice versa),InterMAF根据来自另一模态的注意力加权信息流,融合和更新每个图像区域和每个单词的特征
然后是动态模内注意流(dynamic intra-modality attention flow,DyIntraMAF),用于在每个模态内传递信息流,以提取复杂的模态内关系,视觉区域和语言在同一模态下生成self-attention,并从其它实例聚合注意力权重,虽然信息仅在相同的模态中传播,但使用了其他模态的信息来调节模态内的注意权重和流量,通过这种操作模态内的注意力动态依赖于其它模态。实验证明,DyIntraMAF比仅使用内部信息来实现内部模态信息流要好,该操作是框架的核心
文章的贡献主要包含以下三点:
提出DFAF框架,首次将模间和动态模内信息流集成到一个统一的框架中,以解决VQA任务
框架的核心模块:DyIntraMAF,动态生成各模内的有效注意流,并动态地依赖于其他模内的信息
进行大量的实验和消融实验来检验DFAF框架的有效性,并用框架实现了一个SOTA的VQA模型
Related Work
特征提取
ResNet逐渐取代VGG作为图像特征提取工具
从Faster R-CNN衍生的BUTD model取得了很好的效果
双线性融合
Self-attention
将特征转换为查询特征、关键特征和价值特征,通过查询和关键特征的内积计算不同特征之间的注意矩阵,然后计算原始特征的注意加权和
Co-attention
对于每个单词,可以根据co-attention将图像区域特征聚合到单词,DCN得益于co-attention,在不使用BUTD特征的情况下达到SOTA
其它VQA工作
Dynamic Parameter Prediction和Question-guided Hybrid Convolution用动态预测的参数进行特征融合
Adaptive attention在图像提取时可以跳过注意力(skip attention)
Structured attention采用了注意力图上的MRF模型来更好地模拟注意力的空间分布
Locally weighted deformable neighbours预测偏移量和模型权重
DFAF框架
整体框架如图

首先利用co-attention对两种模态之间的视觉和语言特征进行加权,然后InterMAF模块对图像区域和单词的模态之间的特征进行聚合,学习图像区域和问题之间的交互,然后用DyIntraMAF学习word-to-word和region-to-region的关系,InterMAF和DyIntraMAF模块交替重叠,迭代地传递信息流,最后用一个简单的分类器得到答案
基本的视觉和语言特征提取采用RCNN和GRU
Intermodality Attention Flow
InterMAF首先学习捕捉每一对图像区域和语言特征之间的重要性,然后根据学习到的重要度权值和聚集特征在两种模式之间传递信息流,更新每个单词特征和图像区域特征,这样的信息流过程能够识别视觉区域和单词之间的跨模态关系
首先将每个视觉区域和单词特征转化为查询特征、关键特征和值特征,分别记为代表视觉区域的$R_K$,$R_Q$和$R_V$ $\in R^{\mu \times dim}$,以及代表单词特征的$E_K$,$E_Q$和$E_V$ $\in R^{14 \times dim}$
$Linear$是全连接层,$dim$是两种模态转化后特征的共同维度
通过计算每对视觉区域特征与关键词特征之间的内积$R_QE^T_K$获得原始的注意力权重,用于将信息从单词特征聚合到每个视觉特征,反之亦然
用维数的平方根和softmax对原始权重进行归一化得到两组权重$InterMAF_{R \leftarrow E}$和$InterMAF_{R \to E}$
内积的值与隐藏特征空间的维数成正比,因此需要用隐藏维数的平方根进行归一化
两个InterMAF矩阵捕获了每个图像区域和词对之间的重要性,以$InterMAF_{R \leftarrow E}$为例,每一行代表一个视觉区域和所有词嵌入之间的注意力权重,所有词嵌入到该图像区域特征的信息可以聚合为词值特征$E_V$的加权总和
用于更新视觉区域特征和单词特征的信息流表示为
InterMAF矩阵用于确定信息流的权重
将更新后的特征和原始的特征连接在一起,通过一个全连接层转化为输出特征
InterMAF模块的输出特性将被输入DyIntraMAF模块用于学习模内信息流,进一步更新视觉区域和单词特征,捕获区域-区域和单词-单词关系
Dynamic Intramodality Attention Flow
作者认为模态内关系是跨模关系的补充,比如问题”谁在滑板上”,需要将滑板上方区域与滑板区域联系起来
因此作者用动态注意机制建模这种模内关系
DyIntraMAF模块框架如图
用于捕获区域之间和单词之间重要性的朴素IntraMAF矩阵和InterMAF矩阵十分相似
朴素的IntraMAF只使用模内信息来估计区域和区域之间以及文字和文字之间的重要性,但是有些关键关系只能通过另一个模态的信息来确定,就比如说,即使对于相同的输入图像,不同的视觉区域对之间的关系也应该根据不同的问题进行不同的加权,因此作者提出了DyIntraMAF,用来自其他模态的信息来评估重要度
为了从其它模态中总结条件信息,将视觉区域特征沿着对象索引维度,单词特征沿着单词索引维度做平均池化,然后将两个模态平均池化后的特征转化为维度特征向量来匹配问题的关键特征$R_Q$,$R_K$,$E_Q$,$E_K$,然后通过sigmoid函数之后生成其它模态的通道门控(channel-wise conditioning gates)
两种模态的查询和关键特征由另一种模态的条件门控制
$\odot$是矩阵元素乘,问题和关键特征的通道将会根据其它模态的门控决定被激活或停用,通道选通向量是基于跨模态信息创建的
这个动态的DyIntraMAF矩阵就跟朴素的IntranetMAF矩阵算法一样,只是经过了门控
最后用DyIntraMAF矩阵处理后输出结果
Experiments
在DAFA框架上做的消融实验
和SOTA的比较
DyIntraMAF权重矩阵的可视化,针对问题的不同可以得到不同的注意权重,而IntraMAF是恒定不变的
![支付宝]() 支付宝
支付宝