RUBi [question-only分支]
文章简介
VQA模型倾向于利用答案的出现和问题中的某些模式之间的统计规律来回答问题,虽然它们被设计来合并来自两种模态的信息,但在实践中,它们通常不考虑图像模态,当大多数香蕉都是黄色的时候,模型不需要学习正确的方法来回答香蕉颜色的问题,只要将单词”什么”、”颜色”和”香蕉”与最常见的答案”黄色”联系起来即可,这比通过看图像来判断香蕉的颜色要容易得多
量化每种模态统计捷径数量的一种方法是训练单模态模型,比如在VQAv2中训练的纯语言模型可以在测试集上达到44%的准确率,VQA模型没有放弃这种偏差,因为他们的训练数据集和测试数据集是有着同样的分布,然而在不同分布规律的测试集上评估时,其准确率会显著下降,然而在收集真实数据集时,很难避免这些统计规律,需要采取新的策略来减少来自问题的bias

作者提出了一种训练策略RUBi,用以减少VQA模型的bias,这种策略降低了最biased的样本的重要性,也就是那些不需要看图像模态就能正确分类的样本,它隐式地迫使VQA模型使用两种输入模式,而不是依赖于问题和答案之间的统计规律,作者在训练期间在基础VQA模型的顶部添加一个question-only分支。该分支影响VQA模型,动态调整损失以补偿偏差,通过VQA模型反向传播的梯度对于偏度较大的样本被降低,对于偏度较小的样本被增加。在训练结束时,简单地删除question-only分支
相关工作
真实世界的数据集由于其收集过程而显示出某种形式的固有偏差,因此,机器学习模型倾向于反映这些偏差,因为它们捕获了输入和GT标注之间虚假的相关性,有研究开始识别特定种类的偏差并减少他们,比如有些方法针对性别偏差,人类报告偏差,也有针对实验采集的数据和真实世界数据的偏差,在语言和视觉领域,一些研究评估单模态基线或者是利用语言先验
单模态偏差
尽管被设计为双模态融合,但是VQA模型通常只依靠单模态来解决问题,量化VQA模型可能学习到的单模态偏差的数量的一个有趣的方法是只使用两种模式之一的训练模型,纯问题模型是一个特别强大的baseline,因为可以从问题模态中利用大量的统计规律,通过RUBi学习策略,作者利用这个baseline模型来防止VQA模型学习问题偏差
平衡数据集
一旦识别出单模态偏差,克服这些偏差的一个方法就是创建更平衡的数据集,比如拒绝在一系列相关的问题中抽样来最小化通往正确答案的捷径数量
由于注释的成本,在真实的VQA数据集中做拒绝采样通常是不可能的,另一个解决方案是收集互补的示例来增加任务的难度,即使有了这种额外的平衡,问题的统计偏差仍然存在,并且可以加以利用,因此作者提出了一种方法来减少训练中的单模态偏差,RUBi被设计用于从有偏的数据集中学习无偏的模型,这种学习策略动态地修改损失值,以减少问题的偏差,通过这种方式,减少了某些样本的重要性,增加了互补问题的重要性
架构和学习策略
另一个重要的工作是设计VQA模型来克服数据集的偏差,Agrawal et al提出了一种手工设计的架构GVQA,将VQA的任务分解为两步,第一步定位和识别问题所需的视觉区域,第二步是根据question only的分支来确定答案可能的空间,这种方法需要分别训练多个子模型,而作者提出的方法是端到端的,它们的复杂设计不能直接应用于不同的体系结构,而作者方法是与模型无关的。虽然依赖于一个仅问问题的分支,但在训练结束时删除了它
和本文最为相近的工作是Ramakrishnan et al,这项工作中提出了一种克服VQA模型中语言先验的学习策略。他们首先引进了question-only分支,用来自VQA模型的问题编码作为输入,并产生一个question-only损失,他们使用这种损失的梯度否定(gradient negation)来阻止问题编码器捕获可能被VQA模型利用的偏差。他们还提出了基于VQA模型和纯问题分支输出分布之间的熵差异的损失,这两个损失只反向传播到问题编码器。相比之下,作者的学习策略以完整的VQA模型参数为目标,以更有效地减少不必要的偏差的影响,使用问题分支动态适应分类损失的值,以减少VQA模型的学习偏差
直观对比见下图
RUBi
作者将VQA视为一个分类问题,给定的数据集D由三部分组成,图像v,问题q和答案a,作者需要优化的是函数f中的参数,这个函数f可以表示为
经典学习策略和陷阱
VQA模型的经典学习策略如图所示,在大小为n的数据集上最小化标准交叉熵
它们倾向于依赖一种模态的统计规律来提供准确的预测,而不必考虑另一种模态,举一个极端的例子,对问题模态有强烈偏见的模型总是对香蕉是什么颜色的问题输出黄色。它们不学习使用图像信息,因为在数据集中香蕉不是黄色的例子太少了
RUBi学习策略
—— 用question-only分支来捕捉偏见
测量单模态偏差的一个方法就是训练一个单模态模型,RUBi的关键思是将一个question-only的模型作为VQA模型的一个分支,这将改变主模型的预测
通过这样做,只考虑问题的分支捕获了问题偏差,从而允许VQA模型关注仅使用问题模态无法正确回答的示例
在训练期间,分支结构充当代理,阻止任何形式的VQA模型由学习偏差得到式
结束训练后,直接删除分支,用基本VQA模型来做预测
—— 通过标记预测来防止偏见
在基础VQA模型的预测传递到损失函数之前,将它们与长度为$|A|$的掩码合并,掩码包含每个答案的0到1之间的标量值,该掩码是通过将神经网络$nn_q$的输出通过一个$sigmoid$函数得到的,这个掩码的目的是通过修改VQA模型的预测来动态地改变损失,为了得到新的预测,只要计算原先预测和掩码之间的元素级乘
为了更好地理解这个方法对学习的影响,作者进行了以下两个步骤:
首先减少了大部分偏见样本的重要性,做法是question-only分支输出一个掩码来增加正确答案的分数,同时减少其他答案的分数,因此,对于这些偏见样本,损失要低得多,换句话说,也就是通过VQA的后向传播梯度变得更小,因此减少了这些偏见样本的重要性
过程如图所示
mask影响了VQA的预测结果,使得黄色香蕉的得分从0.8上升到了0.94,从而使得loss从0.22下降为0.06
其次,作者提升了回答错误的样本的重要性,比如遇到绿色香蕉时能够将loss抬高
—— 联合学习过程
利用由两个损失计算出的梯度,作者联合优化了基本VQA模型以及question-only分支的参数,最终loss由两部分组成
$L_{QM}$是联合预测结果的交叉熵损失,$L_{QO}$是question-only预测分支的交叉熵损失
Baseline架构
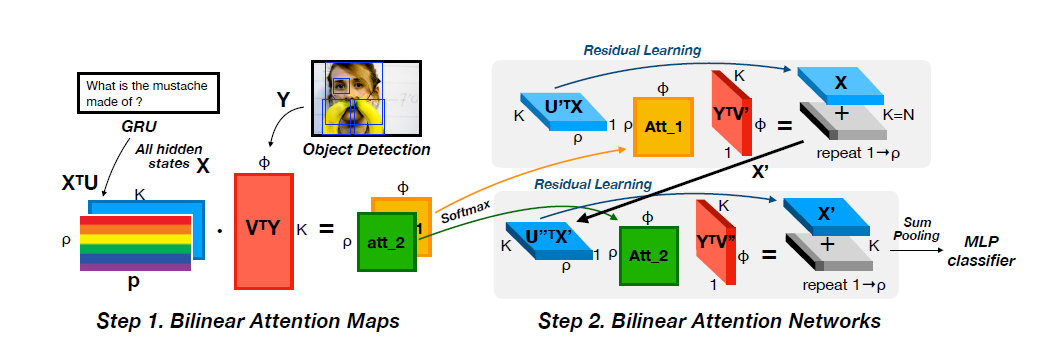
作者的模型结构灵感来自MUREL,图像特征提取采用Faster RCNN,问题特征提取采用GRU,特征融合方法采用的是Bilinear BLOCK fusion,分类则是简单的MLP
实验结果
在VQA-CP v2上和SOTA的比较
在VQA-CP v2上对不同架构的优化
因为消除了bias,所以在VQAv2上反而acc是下降的
RUBi策略同时也改善了attention
![支付宝]() 支付宝
支付宝