Fast R-CNN:引入RoI池化以共享卷积计算
Fast RCNN 在训练速度上达到 RCNN 的9倍,测试速度达到其213倍,同时在PASCAL VOC 2012测试集上mAP达到66%
RCNN和SPPnet
首先回顾一下RCNN中存在的一些问题
SPPnet是RCNN的改良版本,在RCNN中,需要先提取候选框中的特征,然后将每个候选框的特征单独输入CNN中做卷积操作,而SPPnet的核心思想就是从feature map中提取ROI(候选框)特征
这将面临两个问题:
为了解决全连接层输入大小固定的问题,SPPnet提出了空间金字塔池化 (SPP,spatial pyramid pooling),不管输入的特征图大小,均用三种不同尺度的滤波器做池化,最终得到$4\times 4$,$2\times 2$,$1\times 1$大小的256通道的特征图,级联得到固定大小的输出

而映射问题,本质上就是去找到特征图的区域,使得其感受野近似原来的候选框,这里采用的是用步长之积对原坐标进行缩放的方式来定位
计算公式为:
左上角坐标:$\lfloor x/S \rfloor+1$,$\lfloor y/S \rfloor+1$
右下角坐标:$\lceil x/S \rceil-1$,$\lceil y/S \rceil-1$
其中$S$为池化和卷积的步长之积
SPPnet在测试阶段比RCNN快了$10 \sim 100$倍,在训练阶段快了3倍,但是SPPnet依然也存在一些问题
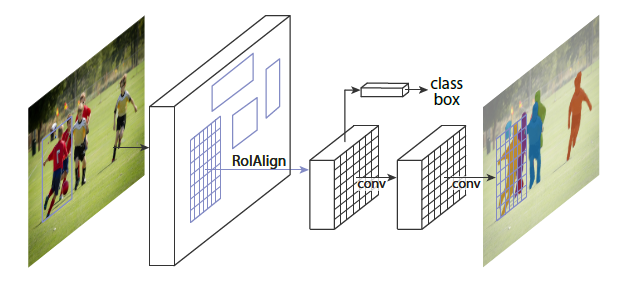
Fast R-CNN
Fast R-CNN的基本架构如下,图描述的非常清楚
主要特点有:
RoI池化层
RoI池化层的目的是将所有输出固定为$H \times W$
文章中将所有RoI用四元组$(r,c,h,w)$定义,即左上角坐标和长宽,RoI池化层的工作原理是将$h \times w$的RoI窗口划分为$H \times W$小块,每块大小为$h/H \times w/W$,最大池化每个小块中的值,输出对应的网格单元,这样就能得到固定大小的输出
SPPnet很难更新空间金字塔池化层前的卷积层是因为反向传播非常低效,其低效性源于每个RoI巨大的感受野 (通常是全图)
为了解决这个问题,作者将采样方式从以RoI为中心的采样转化为以图片为中心的采样,之前的R-CNN和SPPnet都是采用RoI为中心的采样,每个SGD的mini-batch中包含不同图像的样本,不能共享卷积计算,图片为中心的采样是分层采样,先对图像采样(N),然后在采样图像对候选区域采样(R/N,R为批次输入),N调小之后,在一个batch中可以有更多的图在正反向传播时共享特征,提高效率
多任务损失
Fast R-CNN中有两个同级的输出层,分类和回归,分类的目的是计算概率$p=(p_0,\dots,p_K)$,回归则得到物体类的平移和缩放$t^k=(t^k_x,t^k_y,t^k_w,t^k_h)$,两个输出相对应的GT为物体标签类别$u$和回归目标$v$
总的损失函数为
$L_{cls}(p,u)=-log\ p_u$是类别u的负对数损失,最小化正确类别的负对数损失,本质上就是在做最大似然估计
$\lambda$用来调节多任务loss之间的平衡,$[u\ge1]$则限定物体首先存在然后计算第二项loss (背景则不计算第二项)
Loss的第二部分则是对每个坐标或偏移量计算$Smooth_{L1}$
计算公式如下
测试流程
![支付宝]() 支付宝
支付宝