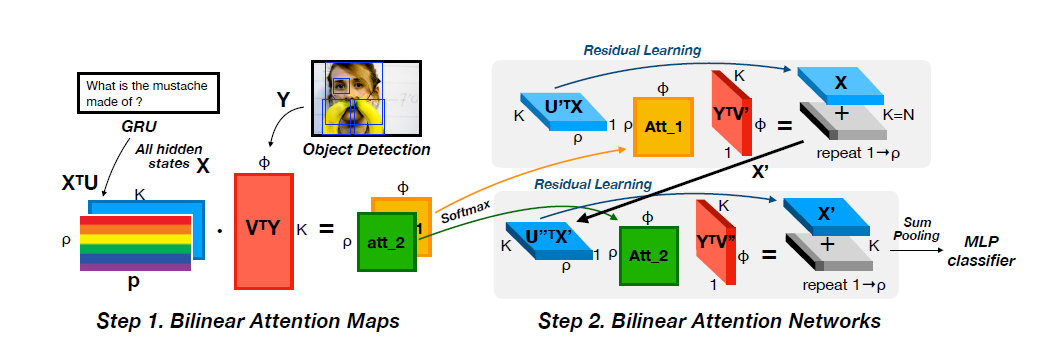
SAN [层叠注意力机制]
从VQA的数据集中可以看出,VQA回答一个问题通常需要多步推理,比如想要根据下图问答问题”what are sitting in
the basket on a bicycle”,那么首先的找到目标basket和bicycle以及问题中的概念sitting in,然后逐渐排除不相关的对象,最后找出最具有代表性的区域来回答问题(dog)

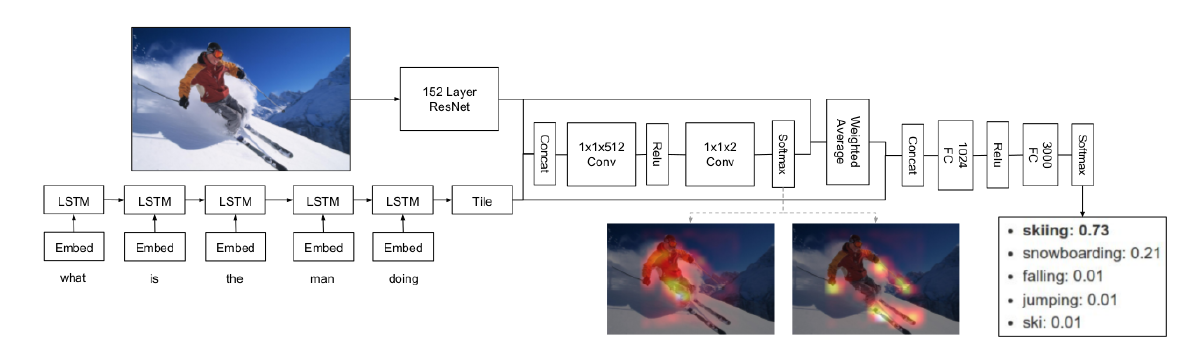
这篇文章提出了允许VQA进行多步推理的层叠注意力网络(SAN),SAN的整体架构如图所示
系统主要包含三个组件,图片特征提取,问题特征提取以及层叠注意力模型,SAN首先利用问题向量对第一层视觉注意层的图像向量进行查询,然后将问题向量与检索到的图像向量组合成一个精细化的查询向量,再对第二层视觉注意层的图像向量进行查询,随着注意力层次的提高,注意力更清晰地集中在跟答案更相关的区域,最后用问题特征和最高层的图像特征来预测答案
文章的主要贡献有:
- 提出了层叠注意力机制(SAN)
- 证明了多层SAN在性能上显著优于之前的SOTA方法
- 可视化了SAN每一个注意层的输出
SAN
Image Model
图片模块用CNN来获得图片特征,与之前的研究不同的是,不采用网络最后一个内积层,而是选择了最后一个池化层,这样能保留原始图像的空间特征
先将图像resize成$448 \times 448$的,然后通过VGG得到$14 \times 14 \times 512$的特征层,所以特征层的每一个像素,都代表了原图中一个$32 \times 32$的区域,最后用单层感知器将每个特征向量转换为与问题向量维数相同的新向量
Question Model
问题模块可以用LSTM或CNN来实现
LSTM
LSTM用$c_t$来储存序列的状态,每一步输入$x_t$,更新$c_t$并输出隐藏状态$h_t$,更新过程采用门控机制,$f_t$是遗忘门,控制多少信息从过去的状态$c_{t-1}$保留,输出们$o_t$控制有多少信息的存储器被馈入输出作为隐藏状态
CNN
CNN提取问题特征的整体过程如图
先对问题做一个嵌入以得到问题的向量表示;然后使用卷积操作,这里的卷积器有三种,分别是unigram,bigram,trigram。第t次的卷积输出和最终得到的feature map则可表示为
对feature进行最大池化,并将三种不同尺寸的池化结果相连接
$h=[\bar{h_1},\bar{h_2},\bar{h_3}]$
h就是最终的结果
Stacked Attention Networks
使用全局图像特征向量来预测答案可能会由于引入与潜在答案无关的区域的噪声而导致结果不理想。相反,通过多重关注层的逐步推理,SAN能够逐渐过滤掉噪音,并确定与答案高度相关的区域
首先通过单层神经网络输入图像和问题特征,然后通过softmax函数生成图像各区域的注意力分布
其中$v_I \in R^{d \times m}$,d是图像特征的维度,m是图像的区域数,$v_Q \in R^d$是d维的向量,$W_{I,A},W_{Q,A} \in R^{k \times d}$, $W_P \in R^{1 \times k}$,$p_I \in R^m$
基于注意力分布,计算每个区域的图像向量的加权和,然后将其与问题向量融合
和简单地将问题向量和全局图像向量结合在一起的模型相比,注意力模型构建了一个信息量更大的u,因为在与问题更相关的视觉区域拥有更高的权重,但对于复杂问题,单一的关注层不足以定位正确区域进行答案预测,因此需要使用多个注意层对上述查询-注意过程进行迭代,每一层都提取更多的细粒度视觉注意信息用于答案预测
重复k次之后计算最终的答案
Experiments
和SOTA的比较,SAN的数字表示用了几个注意力层
双层注意力可视化
错误示例
![支付宝]() 支付宝
支付宝