RAMEN [early fusion]
文章简介
VQA问题要求模型理解并推理视觉-文本内容以回答端到端的关于图片的问题,正确回答这些问题需要模型具备许多能力比如:目标定位,属性检测,活动分类,场景理解,推理,计数等等,第一个VQA数据集包含了真实世界图片以及一系列问题和对应的答案,然而,许多高性能算法只是利用了偏见和表面的相关性,而没有真正理解视觉内容,后来的自然图像VQA数据集努力解决这个问题,VQAv2通过将每个问题与互补的图像和不同的答案练习起来减少了某种形式的语言偏差(bias),TDIUC分析了多种问题和罕见答案的泛化,CVQA测试了概念的组合性,VQAcpv2测试了在训练集和测试集分布不同时的性能
虽然后来的自然图像数据集已经减少了偏差,但这些数据集中的绝大多数问题并没有严格测试推理技能,所以有了合成数据集对这一方面做了一个补充,为了正确评估算法的健壮性,这些数据集的创建者认为算法应该在两个领域进行测试
然而,几乎所有近期的文章都只是在两个领域的其中之一做报告,CLEVR上表现最好的算法并没有在真实VQA数据集中测试,反之亦然,作者发现大多数方法并不能同时在两个领域取得好的表现

文章的主要贡献如下:
- 在8个VQA数据集上对5种SOTA算法进行了比较,发现许多算法不能跨域泛化
- VQA算法通常使用不同的视觉特征和回答词汇,这使得评估性能变得非常困难,作者尝试标准化扩模型使用的组件,比如所有算法采用相同的视觉特征,这需要优化合成场景使用候选区域的方法
- 发现大多数VQA算法都没有理解real-word(?)图像和执行合成推理的能力。所有这些方法在泛化测试中都表现不佳,这表明这些方法仍然在利用数据集的偏差
- 提出了一种新的VQA算法,在所有数据集上与SOTA方法相媲美,并且总体上性能最好
相关工作
VQA数据集
[VQAv1/VQAv2] VQAv1是最早的,端到端的VQA数据集,其中存在很多语言偏差(bias),有些问题与特定的答案紧密相关,VQAv2通过在每个问题上收集导致不同答案的互补图像来减少这种语言偏差,但是其他类型的语言偏差仍然存在,例如推理问题相对于检测问题来说很少
[TDIUC] 通过将问题分成12种不同的类型,从而实现细致入微的任务评估,试图解决问题类型中的偏见,它有度量来评估跨问题类型的泛化
[CVQA] 是VQAv1数据集的重组,用以测试模型的泛化能力,biubiu训练集中包含绿色的盘子和红色的灯,那么测试集中就是红色的盘子和绿色的灯
[VQACPv2] 是VQAv2的一个重组,答案分布在测试集和训练集中是不同的,因为测试和训练集的偏差(bias)是不同的,所以如果能够在这个数据集上表现良好,说明模型比较好地克服了偏差
[CLEVR] 是一个人工合成的数据集,包含虚拟场景和简单的几何图形,数据集中的问题通常需要一长串的复杂推理,问题是由程序生成的,包含五个类型:属性查询,属性比较,是否出现,计数和数字比较
[CLEVR-Humans] CLEVR中的问题从程序提供变为了人类提出
[CLEVR-CoGenT] 测试处理未知组合概念和记忆旧组合概念的能力,其包含两个部分:CoGenT-A以及CoGenT-B,包含互相排斥的形状+颜色组合,如果在CoGenT-A中训练的模型在CoGenT-B中不需要微调就可以表现良好,则说明了模型具备泛化能力,如果在CoGenT-B上微调过的模型依旧在CoGenT-A中表现良好,说明模型具有概念组合记忆能力
作者认为评估VQA系统需要同时测试自然和人工的数据集
VQA算法相关介绍略
RAMEN VQA
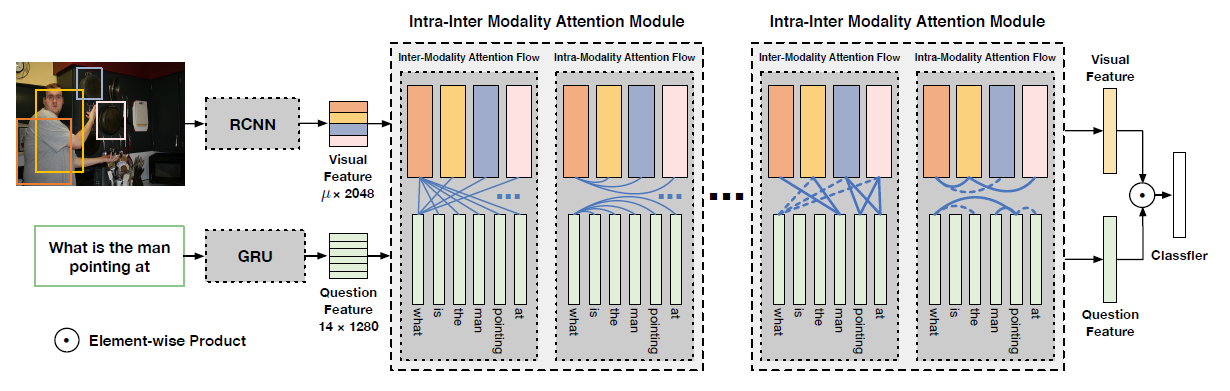
作者提出了Recurrent Aggregation of Multimodal Embeddings Network (RAMEN),既可以适应复杂的自然场景,也能够回答复杂的合成推理链问题,模型框架如下
模型分为三个阶段:
- [视觉和语言特征的早期融合] 已知视觉和语言特征的早期融合(early fusion)有助于合成推理,作者提出了通过连接空间定位的视觉特征和问题特征的早期融合
- [通过共享映射学习双模态嵌入] 连接的视觉+问题特征通过共享网络传递,产生空间定位的双模态嵌入(bimodal embeddings),这个阶段帮助网络了解视觉特征和文本特征之间的相互关系
- [已学双模态嵌入循环聚合] 作者使用双向门控循环单元(bi-GRU)来聚合场景中的双模态嵌入,最终的前向和后向状态需要保留回答问题所需的所有信息
SOTA的自然图像VQA模型使用注意力机制或者双线性池化方法,RAMEN在没有这些机制的情况下也能够达到相同的效果,同样的,相比于在CLEVR数据集上的SOTA模型,RAMEN不适用任何推理单元和预定义模块,然而,实验证明它有合成推理的能力
模型定义
RAMEN的输入是一个问题嵌入q和n个图片候选区域$r_i$,候选区域包括视觉特征以及空间位置,RAMEN首先将每个候选区域和问题向量连接,随后进行批归一化
$\oplus$表示矩阵连接
随后$c_i$向量将通过一个函数F,混合特征以产生双模态的嵌入$b_i=F(c_i)$,F是残差连接的MLP
然后将双模态嵌入和原始问题嵌入连接
A函数采用了bi-GRU,A的输出由前向GRUs和后向GRUs的最终状态连接而成,最后将RAMEN嵌入a传入预测答案的分类器
实现细节
[输入表示] 通过预训练的GloVe向量将问题表示为300-d的嵌入,然后用GRU对其进行处理,得到一个1024维的嵌入问题,每一个候选区域[R2560]包含bottom-up的2048-d的cnn特征,以及512-d的空间信息,将每个候选区域划分为$16\times16$带有坐标信息的网格,平展为512-d向量
[模型配置] F采用了是4层的MLP,包含1024单元,采用swish非线性激活函数,在第2,3,4层有残差连接,聚合器A是一个单层的bi-GRU,包含1024维隐藏状态,所以前向和后向状态的联合产生了2048维的嵌入,嵌入通过一个2048维全连接的swish层进行投影,然后是一个输出分类层,该层在数据集中对每个可能的答案都有一个单元
[训练细节] RAMEN是用Adamax优化的,follow了BAN,在前四个epoch使用渐进的学习速度热身($2.5\times epoch\times 10^{-4}$),在epoch为5到10采用$5\times 10^{-4}$,然后以0.25每两个epoch的速率衰减,minibatch的大小为64
实验结果
和两个领域的SOTA结果的比较,蓝框表示表现前三
消融实验
样例展示
![支付宝]() 支付宝
支付宝